[아이티윌 오라클 DBA 과정 91기] 251023 TIL
2025. 10. 23. 17:45ㆍCourses/아이티윌 오라클 DBA 과정
문제
-- [문제26] 80 부서에 근무하는 사원들의 last_name, job_id, department_name, city 출력해주세요.
SELECT e.last_name, e.job_id, d.department_name, l.city
FROM hr.employees e, hr.departments d, hr.locations l
WHERE e.department_id = d.department_id
AND d.location_id = l.location_id
AND e.department_id = 80;JOIN(조인)
2. equi join (cont.)
SELECT count(*)
FROM hr.employees
WHERE department_id = 20; -- 2건
SELECT e.last_name, e.job_id, d.department_name
FROM hr.employees e, hr.departments d
WHERE e.department_id = d.department_id
AND e.department_id = 20; -- 2건
------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 2 |00:00:00.01 | 4 |
| 1 | NESTED LOOPS | | 1 | 2 | 2 |00:00:00.01 | 4 |
| 2 | TABLE ACCESS BY INDEX ROWID| DEPARTMENTS | 1 | 1 | 1 |00:00:00.01 | 2 |
|* 3 | INDEX UNIQUE SCAN | DEPT_ID_PK | 1 | 1 | 1 |00:00:00.01 | 1 |
| 4 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 1 | 2 | 2 |00:00:00.01 | 2 |
|* 5 | INDEX RANGE SCAN | EMP_DEPARTMENT_IX | 1 | 2 | 2 |00:00:00.01 | 1 |
------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("D"."DEPARTMENT_ID"=20)
5 - access("E"."DEPARTMENT_ID"=20)- employees는 M쪽 집합, departments는 1쪽 집합
- employees는 department_id를 중복해서 가지지만, departments는 department_id를 유니크하게 가짐
- 결과 집합은 조건에 만족하는 M쪽 집합 데이터 개수만큼 나옴
- 조인 조건 컬럼 데이터가 null 인 데이터는 제외
- 그 이상 나온다면 쿼리를 잘못 작성한 것
e.department_id = d.department_id and e.department_id = 20- 조건절 이행 발생
- A = B, B = C 이면 A = C
- 따라서 d.department_id = 20
3. outer join
- 키 값이 일치되는 데이터, 키 값이 일치되지 않은 데이터도 추출하는 조인
- 한 쪽에만 (+)
- 기준 테이블 반대 테이블에 붙임
-- employees 테이블을 기준으로 조인, 부서가 없는 사원도 조회됨
SELECT e.last_name, e.job_id, d.department_name
FROM hr.employees e, hr.departments d
WHERE e.department_id = d.department_id(+);
-- departments 테이블을 기준으로 조인, 사원이 없는 부서도 조회됨
SELECT e.last_name, e.job_id, d.department_name
FROM hr.employees e, hr.departments d
WHERE e.department_id(+) = d.department_id;
-- 양쪽에 (+)는 불가, 오류 발생
SELECT e.last_name, e.job_id, d.department_name
FROM hr.employees e, hr.departments d
WHERE e.department_id(+) = d.department_id(+);
3개 이상의 테이블 outer join
SELECT e.last_name, e.job_id, d.department_name, l.city
FROM hr.employees e, hr.departments d, hr.locations l
WHERE e.department_id = d.department_id(+)
AND d.location_id = l.location_id(+);
- locations 테이블에도 (+)를 해줘야 함
- employees와 departments에 outer join을 수행한 결과 집합에서 Grant 사원은 부서가 없기 때문에 location 정보도 없음
- 따라서 locations 테이블과 조인할 때 outer join을 하지 않으면 Grant 사원에 대한 정보가 누락됨
4. self join
- 자신의 테이블을 참조할 때 사용하는 조인
SELECT w.employee_id, w.last_name, m.employee_id, m.last_name
FROM hr.employees w, hr.employees m
WHERE w.manager_id = m.employee_id;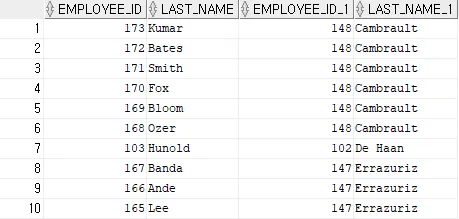
- 최고 직급인 King 사원은 관리자가 없기 때문에 누락됨 → outer join 이용
SELECT w.employee_id, w.last_name, m.employee_id, m.last_name
FROM hr.employees w, hr.employees m
WHERE w.manager_id = m.employee_id(+);
5. non equi join
- equi join(=) 할 수 없는 다른 비교 연산자를 사용하는 조인 기법
- 값을 범위로 조인하려는 경우 많이 사용
SELECT e.employee_id, e.salary, j.grade_level
FROM hr.employees e, hr.job_grades j
WHERE e.salary BETWEEN j.lowest_sal AND j.highest_sal;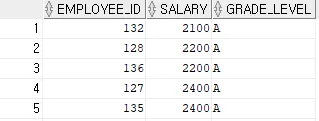
SELECT e.employee_id, e.salary, j.grade_level, d.department_name
FROM hr.employees e, hr.job_grades j, hr.departments d
WHERE e.salary BETWEEN j.lowest_sal AND j.highest_sal
AND e.department_id = d.department_id(+);
ANSI(Americain National Standards Institue) SQL JOIN 문법
1. natural join
- 조인 조건 술어를 자동으로 만들어 줌
- 양쪽 테이블의 동일한 이름의 모든 컬럼을 기준으로 조인 조건 술어를 만들어 줌
SELECT d.department_name, l.city
FROM hr.departments d, hr.locations l
WHERE d.location_id = l.location_id;
-- 위 쿼리와 동일
SELECT d.department_name, l.city
FROM hr.departments d NATURAL JOIN hr.locations l;주의

- employees 테이블의 manager_id와 departments 테이블의 manager_id는 컬럼명은 동일하지만 업무적으로 성격이 다른 컬럼
- manager_id를 기준으로 조인할 경우 문제 발생
- natural join의 경우 양쪽 테이블에서 동일한 이름을 가지는 모든 컬럼을 기준으로 조인하기 때문에 업무적으로 맞지 않는 데이터를 추출하게 됨
SELECT d.department_name, l.location_id, l.city
FROM hr.departments d NATURAL JOIN hr.locations l;
- natural join 시 조인 컬럼에 테이블 별칭 사용 불가 → 오류 발생
2. JOIN USING
- 조인 조건의 기준 컬럼을 지정
- using 절에 사용된 기준 컬럼은 테이블 지정 시 오류 발생
SELECT e.employee_id, d.department_name
FROM hr.employees e JOIN hr.departments d
USING(department_id);오류
SELECT e.employee_id, d.department_name
FROM hr.employees e JOIN hr.departments d
USING(d.department_id);
SELECT e.employee_id, d.department_id, d.department_name
FROM hr.employees e JOIN hr.departments d
USING(department_id);
SELECT e.employee_id, d.department_name
FROM hr.employees e JOIN hr.departments d
USING(department_id)
WHERE d.department_id IN (10, 20);
3개 이상의 테이블 조인
SELECT e.employee_id, department_id, d.department_name, l.city
FROM hr.employees e JOIN hr.departments d
USING(department_id)
JOIN hr.locations l
USING(location_id)
WHERE department_id IN (10, 20);- JOIN … USING() 순으로 반복해서 기술
3. JOIN ON
- ON 절을 이용해서 조인 조건 술어를 직접 만들어 사용
SELECT e.employee_id, d.department_id, d.department_name
FROM hr.employees e JOIN hr.departments d
ON e.department_id = d.department_id;오류
SELECT e.employee_id, d.department_id, d.department_name
FROM hr.employees e JOIN hr.departments d
WHERE e.department_id = d.department_id;
- 조인 조건은 ON절로 작성해야 함
- WHERE 절을 사용하려면 Oracle 조인 방식으로 사용해야 함
SELECT e.employee_id, d.department_id, d.department_name
FROM hr.employees e, hr.departments d
WHERE e.department_id = d.department_id;3개 이상의 테이블 조인
SELECT e.employee_id, d.department_id, d.department_name, l.city
FROM hr.employees e JOIN hr.departments d
ON e.department_id = d.department_id
JOIN hr.locations l
ON d.location_id = l.location_id;- JOIN … ON … 순으로 반복해서 기술
non equi join
SELECT e.employee_id, e.salary, j.grade_level
FROM hr.employees e JOIN hr.job_grades j
ON e.salary BETWEEN j.lowest_sal AND j.highest_sal;
SELECT e.employee_id, e.last_name, e.salary, j.grade_level
FROM hr.employees e JOIN hr.job_grades j
ON e.salary >= j.lowest_sal AND e.salary <= j.highest_sal
WHERE last_name LIKE '%a%';self join
SELECT w.employee_id, w.last_name, m.employee_id, m.last_name
FROM hr.employees w JOIN hr.employees m
ON w.manager_id = m.employee_id;inner join
- join = inner join
- using 절에서도 사용 가능
SELECT e.employee_id, d.department_id, d.department_name
FROM hr.employees e INNER JOIN hr.departments d
ON e.department_id = d.department_id;
SELECT e.employee_id, department_id, d.department_name
FROM hr.employees e INNER JOIN hr.departments d
USING (department_id);4. OUTER JOIN
- 키 값이 일치되는 데이터, 키 값이 일치되지 않은 데이터를 추출하는 조인
LEFT OUTER JOIN
SELECT e.last_name, e.job_id, d.department_name
FROM hr.employees e, hr.departments d
WHERE e.department_id = d.department_id(+);
SELECT e.last_name, e.job_id, d.department_name
FROM hr.employees e LEFT OUTER JOIN hr.departments d
ON e.department_id = d.department_id;RIGHT OUTER JOIN
SELECT e.last_name, e.job_id, d.department_name
FROM hr.employees e, hr.departments d
WHERE e.department_id(+) = d.department_id;
SELECT e.last_name, e.job_id, d.department_name
FROM hr.employees e RIGHT OUTER JOIN hr.departments d
ON e.department_id = d.department_id;FULL OUTER JOIN
SELECT e.last_name, e.job_id, d.department_name
FROM hr.employees e FULL OUTER JOIN hr.departments d
ON e.department_id = d.department_id;- Oracle 조인에서는 양쪽에 (+) 붙이면 오류
- ANSI 조인에서는 FULL OUTER JOIN으로 가능
3개 이상의 테이블 조인
SELECT e.last_name, e.job_id, d.department_name, l.city
FROM hr.employees e LEFT OUTER JOIN hr.departments d
ON e.department_id = d.department_id
LEFT OUTER JOIN hr.locations l
ON d.location_id = l.location_id;5. CARTESIAN PRODUCT
- 조인 조건이 생략된 경우
- 조인 조건이 잘못 생성된 경우
- 첫 번째 테이블 행수와 두 번째 테이블 행수가 곱해짐
SELECT e.last_name, e.job_id, d.department_name
FROM hr.employees e, hr.departments d;
SELECT e.last_name, e.job_id, d.department_name
FROM hr.employees e CROSS JOIN hr.departments d;- ANSI 조인에서는 CROSS JOIN 키워드 사용
문제
-- [문제27] 2006년도에 입사한 사원들의 부서이름별 급여의 총액, 평균을 출력해주세요.
-- 1) 오라클 전용
SELECT d.department_name 부서이름, sum(e.salary) 급여총액, avg(e.salary) 급여평균
FROM hr.employees e, hr.departments d
WHERE e.department_id = d.department_id
AND e.hire_date between to_date('20060101','yyyymmdd') and to_date('20070101', 'yyyymmdd') - 1/24/60/60
GROUP BY d.department_name;
-- 2) ANSI 표준
SELECT d.department_name 부서이름, sum(e.salary) 급여총액, avg(e.salary) 급여평균
FROM hr.employees e JOIN hr.departments d
ON e.department_id = d.department_id
AND e.hire_date between to_date('20060101','yyyymmdd') and to_date('20070101', 'yyyymmdd') - 1/24/60/60
GROUP BY d.department_name;-- [문제28] 2007년도에 입사한 사원들의 도시이름별 급여의 총액, 평균을 출력해주세요.
-- 단 부서 배치를 받지 않은 사원들의 정보도 출력해주세요.
-- 1) 오라클 전용
SELECT l.city 도시이름, sum(e.salary) 급여총액, avg(e.salary) 급여평균
FROM hr.employees e, hr.departments d, hr.locations l
WHERE e.department_id = d.department_id(+)
AND d.location_id = l.location_id(+)
AND e.hire_date between to_date('20070101','yyyymmdd') and to_date('20080101', 'yyyymmdd') - 1/24/60/60
GROUP BY l.city;
-- 2) ANSI 표준
SELECT l.city 도시이름, sum(e.salary) 급여총액, avg(e.salary) 급여평균
FROM hr.employees e LEFT OUTER JOIN hr.departments d
ON e.department_id = d.department_id
LEFT OUTER JOIN hr.locations l
ON d.location_id = l.location_id
WHERE e.hire_date between to_date('20070101','yyyymmdd') and to_date('20080101', 'yyyymmdd') - 1/24/60/60
GROUP BY l.city;-- [문제29] 관리자보다 먼저 입사한 사원의 이름과 입사일 및 해당 관리자의 이름과 입사일 출력해주세요.
-- 1) 오라클 전용
SELECT w.last_name 사원이름, w.hire_date 사원입사일, m.last_name 관리자이름, m.hire_date 관리자입사일
FROM hr.employees w, hr.employees m
WHERE w.manager_id = m.employee_id
AND w.hire_date < m.hire_date;
-- 2) ANSI 표준
SELECT w.last_name 사원이름, w.hire_date 사원입사일, m.last_name 관리자이름, m.hire_date 관리자입사일
FROM hr.employees w JOIN hr.employees m
ON w.manager_id = m.employee_id
WHERE w.hire_date < m.hire_date;Subquery(서브쿼리)
- SQL 문 안의 SELECT문
- SELECT 문의 서브쿼리는 괄호()로 묶어야 함
- SELECT 문의 서브쿼리는 GROUP BY 절을 제외한 어디서든지 사용 가능
-- 110번 사원의 급여보다 더 많은 급여를 받는 사원 조회
-- 110번 사원 급여 조회 : 8200
SELECT salary
FROM hr.employees e
WHERE e.employee_id = 110;
-- salary가 8200 이상인 사원 조회
SELECT *
FROM hr.employees
WHERE salary > (SELECT salary
FROM hr.employees e
WHERE e.employee_id = 110); - main query, outer query : 괄호 밖의 쿼리
- inner query, subquery : 괄호 안의 쿼리
중첩 서브 쿼리(Nested Subquery)
- inner query(subquery) 먼저 수행
- 1번에서 수행한 값을 가지고 main(outer) query 수행
단일행 서브 쿼리
- 서브 쿼리의 결과가 단일 값으로 나오는 서브 쿼리
- 단일행 비교 연산자(= , >, >=, <, <=, <>, !=, ^=)
SELECT *
FROM hr.employees
WHERE salary > (SELECT salary
FROM hr.employees
WHERE last_name = 'King'); 
- last_name이 King인 사원은 여러 명 존재
- 서브 쿼리에서 리턴 되는 값이 여러 개일 경우 단일행 비교 연산자를 사용하면 오류 발생
문제
-- [문제30] 최고 급여를 받는 사원들의 정보를 출력해주세요.
SELECT *
FROM hr.employees
WHERE salary = (SELECT max(salary)
FROM hr.employees);HAVING 절 서브쿼리
- HAVING은 그룹 함수의 결과를 제한하는 절
- HAVING 절의 비교 연산자 오른쪽 부분을 () 묶어서 서브쿼리 사용
SELECT department_id, sum(salary)
FROM hr.employees
GROUP BY department_id
HAVING sum(salary) > (SELECT min(salary)
FROM hr.employees
WHERE department_id = 40);문제
-- [문제31] 평균 급여가 가장 낮은 부서번호, 평균급여를 출력해주세요.
SELECT department_id, avg(salary)
FROM hr.employees
GROUP BY department_id
HAVING avg(salary) = (SELECT min(avg(salary))
FROM hr.employees
GROUP BY department_id);'Courses > 아이티윌 오라클 DBA 과정' 카테고리의 다른 글
| [아이티윌 오라클 DBA 과정 91기] 251027 TIL (0) | 2025.10.27 |
|---|---|
| [아이티윌 오라클 DBA 과정 91기] 251024 TIL (0) | 2025.10.24 |
| [아이티윌 오라클 DBA 과정 91기] 251022 TIL (0) | 2025.10.22 |
| [아이티윌 오라클 DBA 과정 91기] 251021 TIL (0) | 2025.10.21 |
| [아이티윌 오라클 DBA 과정 91기] 251020 TIL (0) | 2025.10.20 |