[아이티윌 오라클 DBA 과정 91기] 260202 TIL
2026. 2. 2. 20:58ㆍCourses/아이티윌 오라클 DBA 과정
GROUP COMMIT
테이블 생성
SYS@ora19c> drop table hr.emp purge;
Table dropped.
SYS@ora19c> create table hr.emp tablespace users as select * from hr.employees;
Table created.
SYS@ora19c> select n.name, sum(s.value)
from v$sesstat s, v$statname n
where n.name in ('redo synch writes', 'user commits', 'user rollbacks')
and s.statistic# = n.statistic#
and s.sid = (select sid from v$session where username = 'HR')
group by n.name; 3 4 5 6
NAME SUM(S.VALUE)
-------------------------------------------------- ------------
user rollbacks 0
redo synch writes 1
user commits 0
SYS@ora19c> select event, total_waits, time_waited
from v$session_event
where sid = (select sid from v$session where username = 'HR')
and event = 'log file sync'; 3 4
EVENT TOTAL_WAITS TIME_WAITED
---------------------------------------------------------------- ----------- -----------
log file sync 1 1
Update 수행 후 COMMIT
첫 번째 commit
HR@ora19c> update hr.emp
set salary = salary * 1.1
where employee_id = 100; 2 3
1 row updated.
HR@ora19c> commit;
Commit complete.SYS@ora19c> select n.name, sum(s.value)
from v$sesstat s, v$statname n
where n.name in ('redo synch writes', 'user commits', 'user rollbacks')
and s.statistic# = n.statistic#
and s.sid = (select sid from v$session where username = 'HR')
group by n.name; 2 3 4 5 6
NAME SUM(S.VALUE)
-------------------------------------------------- ------------
user rollbacks 0
redo synch writes 3
user commits 1
SYS@ora19c> select event, total_waits, time_waited
from v$session_event
where sid = (select sid from v$session where username = 'HR')
and event = 'log file sync'; 2 3 4
EVENT TOTAL_WAITS TIME_WAITED
---------------------------------------------------------------- ----------- -----------
log file sync 3 2
- redo synch writes 2, user commits 1 증가
두 번째 commit
HR@ora19c> update hr.emp
set salary = salary * 1.1
where employee_id = 101; 2 3
1 row updated.
HR@ora19c> commit;
Commit complete.SYS@ora19c> select n.name, sum(s.value)
from v$sesstat s, v$statname n
where n.name in ('redo synch writes', 'user commits', 'user rollbacks')
and s.statistic# = n.statistic#
and s.sid = (select sid from v$session where username = 'HR')
group by n.name; 2 3 4 5 6
NAME SUM(S.VALUE)
-------------------------------------------------- ------------
user rollbacks 0
redo synch writes 4
user commits 2
SYS@ora19c> select event, total_waits, time_waited
from v$session_event
where sid = (select sid from v$session where username = 'HR')
and event = 'log file sync'; 2 3 4
EVENT TOTAL_WAITS TIME_WAITED
---------------------------------------------------------------- ----------- -----------
log file sync 4 3- redo synch writes 1, user commits 1 증가
세 번째 commit
HR@ora19c> update hr.emp
set salary = salary * 1.1
where employee_id = 200; 2 3
1 row updated.
HR@ora19c> commit;
Commit complete.SYS@ora19c> select n.name, sum(s.value)
from v$sesstat s, v$statname n
where n.name in ('redo synch writes', 'user commits', 'user rollbacks')
and s.statistic# = n.statistic#
and s.sid = (select sid from v$session where username = 'HR')
group by n.name; 2 3 4 5 6
NAME SUM(S.VALUE)
-------------------------------------------------- ------------
user rollbacks 0
redo synch writes 5
user commits 3
SYS@ora19c> select event, total_waits, time_waited
from v$session_event
where sid = (select sid from v$session where username = 'HR')
and event = 'log file sync'; 3 4
EVENT TOTAL_WAITS TIME_WAITED
---------------------------------------------------------------- ----------- -----------
log file sync 5 4- redo synch writes 1, user commits 1 증가
GROUP COMMIT
- PLSQL 블록 내에서 3번 COMMIT을 수행하더라도 그룹 COMMIT 1번만 LGWR 작동
SYS@ora19c> select n.name, sum(s.value)
from v$sesstat s, v$statname n
where n.name in ('redo synch writes', 'user commits', 'user rollbacks')
and s.statistic# = n.statistic#
and s.sid = (select sid from v$session where username = 'HR')
group by n.name; 2 3 4 5 6
NAME SUM(S.VALUE)
-------------------------------------------------- ------------
user rollbacks 0
redo synch writes 1
user commits 0
SYS@ora19c> select event, total_waits, time_waited
from v$session_event
where sid = (select sid from v$session where username = 'HR')
and event = 'log file sync'; 2 3 4
EVENT TOTAL_WAITS TIME_WAITED
---------------------------------------------------------------- ----------- -----------
log file sync 1 0HR@ora19c> declare
type numlist is table of number;
v_num numlist := numlist(100, 101, 200);
begin
for i in v_num.first..v_num.last loop
update hr.emp
set salary = salary * 1.1
where employee_id = v_num(i);
commit;
end loop;
end;
/ 2 3 4 5 6 7 8 9 10 11 12 13
PL/SQL procedure successfully completed.SYS@ora19c> select n.name, sum(s.value)
from v$sesstat s, v$statname n
where n.name in ('redo synch writes', 'user commits', 'user rollbacks')
and s.statistic# = n.statistic#
and s.sid = (select sid from v$session where username = 'HR')
group by n.name; 2 3 4 5 6
NAME SUM(S.VALUE)
-------------------------------------------------- ------------
user rollbacks 0
redo synch writes 2
user commits 3
SYS@ora19c> select event, total_waits, time_waited
from v$session_event
where sid = (select sid from v$session where username = 'HR')
and event = 'log file sync'; 2 3 4
EVENT TOTAL_WAITS TIME_WAITED
---------------------------------------------------------------- ----------- -----------
log file sync 2 1- user commit은 3으로 늘어났지만 redo synch writes는 1만 증가 → LGWR는 1번만 작동
- log file sync 이벤트도 1번만 발생
SQL 튜닝
- SQL 튜닝은 SQL 문을 최적화하여 빠른 시간 내에 원하는 결과 값을 얻기 위한 작업
- SQL 튜닝의 시작은 SQL 의미(작성 의미)를 제대로 파악하는 것
- SQL의 의미를 정확히 파악하지 못한다면 원본 SQL에서 추출하고자 했던 결과 집합이 아닌 다른 집합을 추출할 수도 있기 때문
- SQL의 의미를 파악하는 것이 성능 문제를 유발하는 SQL에 대한 개선의 시작이라고 말할 수 있음
select * from hr.emp where employee_id = 100;데이터 처리 결정
- full table scan
- rowid scan
- by user rowid
- by index rowid
Full Table Scan
- 많은 양의 데이터 검색 시 유용
- 첫 번째 블록부터 마지막 사용한 블록(High Water Mark) 까지 읽어오는 방식
- HWM(High Water Mark) 란 저장 공간을 갖는 세그먼트 영역에서 사용한 적이 있는 블록과 사용한 적이 없는 블록의 경계점을 의미
- Multi Block I/O 발생
- 한 번의 I/O가 발생할 때
db_file_multiblock_read_count파라미터에 설정되어 있는 블록 수 만큼 읽어옴 - OS : 보통 1M 단위로 I/O 발생(디스크에서 메모리로 읽어오는 기준)
- Extent 크기에 종속됨
db file scattered read대기 이벤트 발생
# block 사이즈
SYS@ora19c> show parameter db_block_size
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
db_block_size integer 8192
# multiblock 시 한 번의 I/O call 당 읽어오는 블록의 수
SYS@ora19c> show parameter db_file_multiblock_read_count
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
db_file_multiblock_read_count integer 57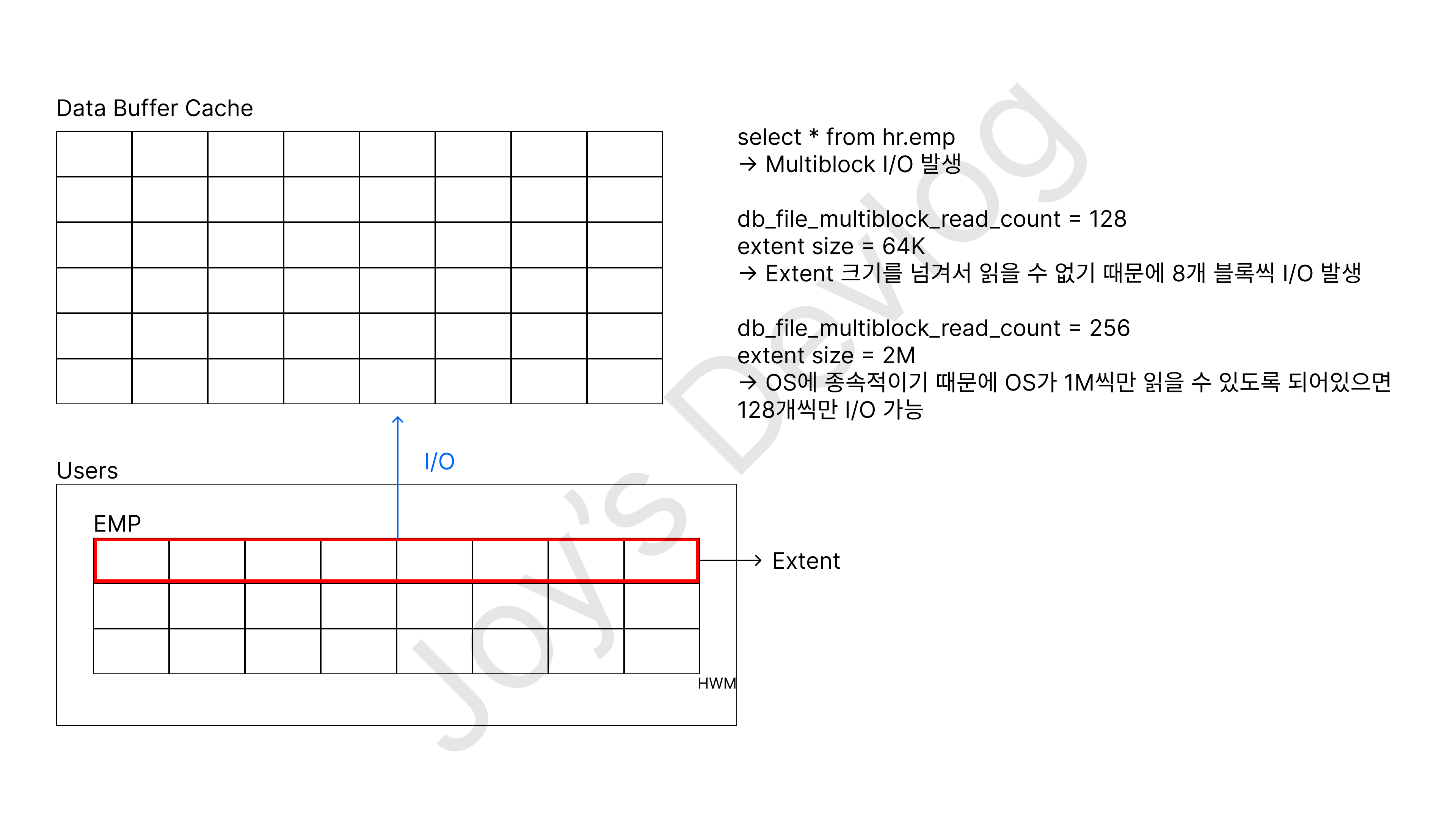
Direct Path Read
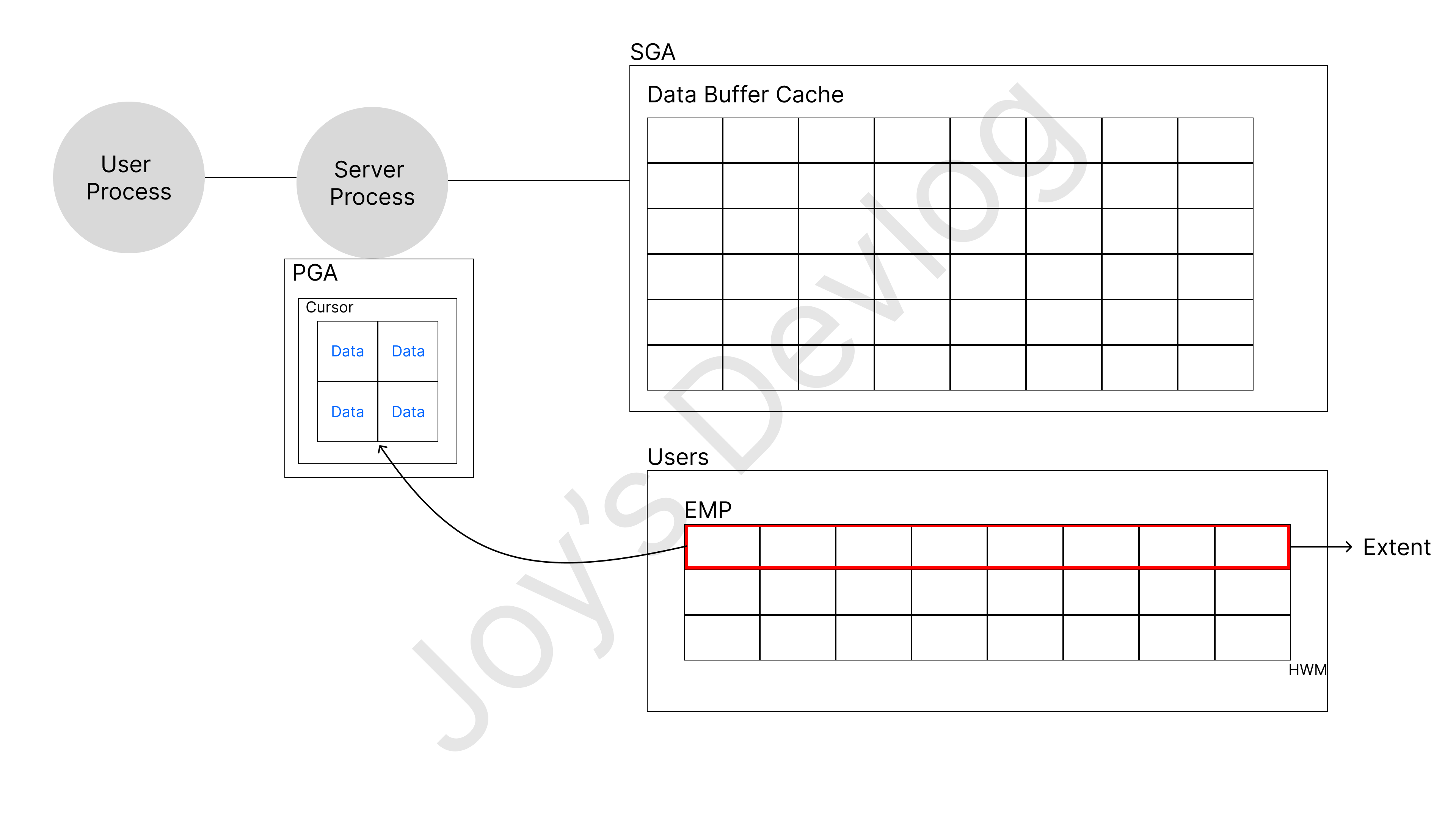
- Data Buffer Cache에 캐싱해놓고 읽으려면 Free Buffer도 확보해야 하고 그만큼 Latch 및 Lock도 여러 번 획득해야 함
- 데이터 파일에서 읽은 데이터 블록을 PGA 공간에 바로 읽어들임으로써 위와 같은 비효율 해소
autotrace
# autotrace 활성화
SYS@ora19c> set autot traceonly exp
SYS@ora19c> select * from hr.emp where employee_id = 100;
Execution Plan
----------------------------------------------------------
Plan hash value: 3956160932
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 69 | 3 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| EMP | 1 | 69 | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("EMPLOYEE_ID"=100)
# autotrace 해제
SYS@ora19c> set autot off - 실행 계획에
TABLE ACCESS FULL이 뜸
full table scan 성능 개선
- 병렬 처리 작업(
parallel또는parallel_index힌트 사용), direct path read
select /*+ full(e) paralle(e,2) */ * from emp e;- db_file_multiblock_read_count 파라미터 값을 조정
# 세션 레벨에서 수정 가능
SYS@ora19c> alter session set db_file_multiblock_read_count = 128;
Session altered.
SYS@ora19c> show parameter db_file_multiblock_read_count
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
db_file_multiblock_read_count integer 128direct path read
- 데이터 파일에서 읽은 블록을 데이터 버퍼 캐시를 사용하지 않고 PGA 영역으로 바로 읽어옴
rowid scan
- user rowid, index rowid 를 이용하여 소량의 데이터 검색 시 유용
- single block I/O 발생
db file sequential read대기 이벤트 발생- 디스크에서 메모리로 한 개의 블록을 읽어올 때 발생하는 대기 이벤트
rowid 조회
SYS@ora19c> select
employee_id,
rowid extended_format,
dbms_rowid.rowid_object(rowid) as data_object_id,
dbms_rowid.rowid_relative_fno(rowid) as file_no,
dbms_rowid.rowid_block_number(rowid) as block_no,
dbms_rowid.rowid_row_number(rowid) as row_slot_no,
dbms_rowid.rowid_to_restricted(rowid,0) retricted_format
from hr.emp
where employee_id = 100; 2 3 4 5 6 7 8 9 10
EMPLOYEE_ID EXTENDED_FORMAT DATA_OBJECT_ID FILE_NO BLOCK_NO ROW_SLOT_NO RETRICTED_FORMAT
----------- ------------------ -------------- ---------- ---------- ----------- ------------------
100 AAAScmAAHAAAAHbAAA 75558 7 475 0 000001DB.0000.0007autotrace
SYS@ora19c> set autot traceonly exp
SYS@ora19c> select * from hr.emp where rowid = 'AAAScmAAHAAAAHbAAA';
Execution Plan
----------------------------------------------------------
Plan hash value: 1116584662
-----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 69 | 1 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY USER ROWID| EMP | 1 | 69 | 1 (0)| 00:00:01 |
------------------------------------------------------------------------------------ 실행 계획에
TABLE ACCESS BY USER ROWID이 뜸
Index Scan
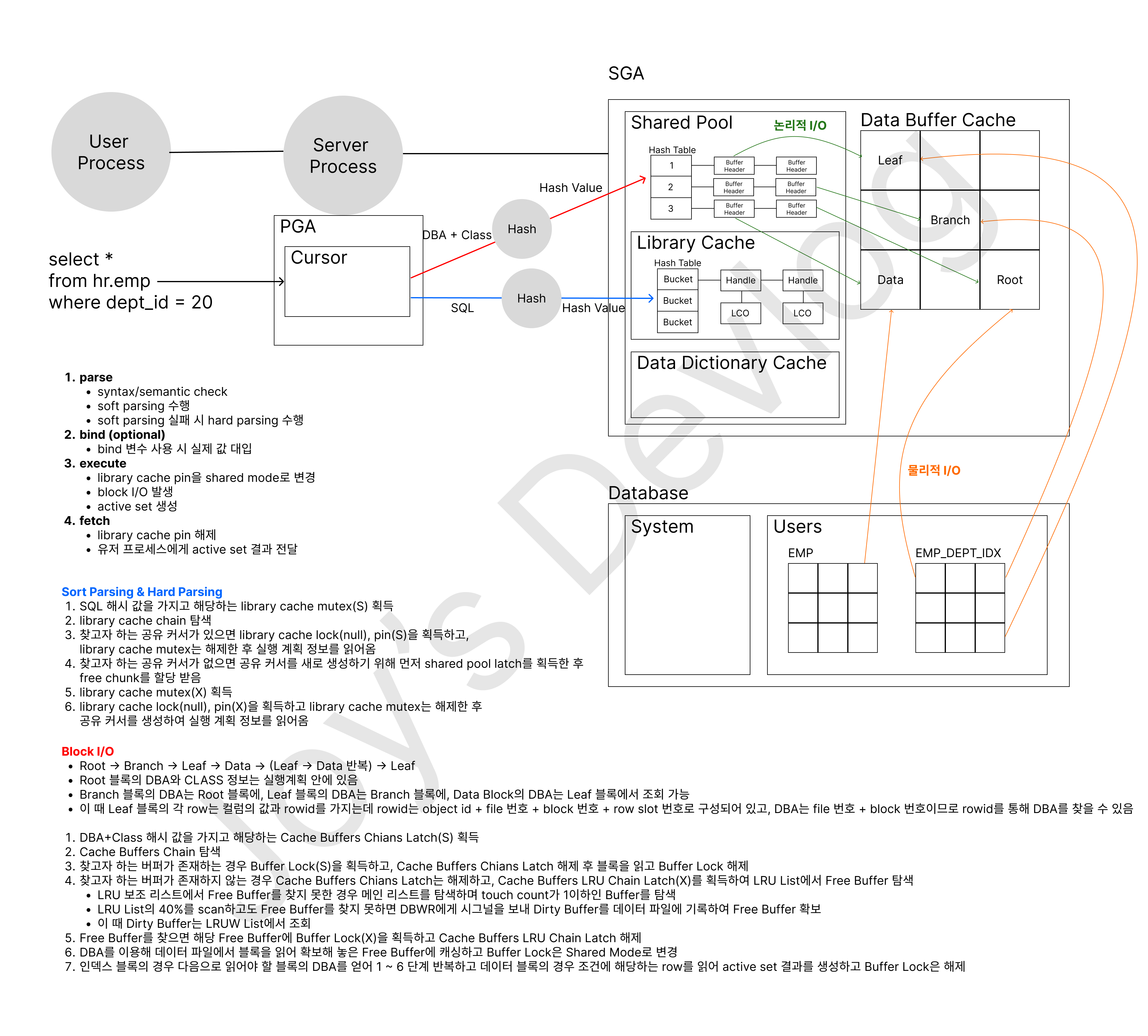
- 인덱스는 대용량 테이블에서 필요한 데이터만 빠르고 효율적으로 액세스할 목적으로 사용하는 객체
index range scan
- root block → branch block → leaf block → 실제 데이터 블록 → leaf bolck(one plus scan)
인덱스 생성
HR@ora19c> create index hr.emp_idx on hr.emp(employee_id) tablespace users;
Index created.HR@ora19c> select ix.index_name, ix.uniqueness, ic.column_name
from user_indexes ix, user_ind_columns ic
where ix.index_name = ic.index_name
and ix.table_name = 'EMP'; 2 3 4
INDEX_NAME UNIQUENES COLUMN_NAME
------------------------------ --------- ------------------------------
EMP_IDX NONUNIQUE EMPLOYEE_IDautotrace
SYS@ora19c> select * from hr.emp where employee_id = 100;
Execution Plan
----------------------------------------------------------
Plan hash value: 3589413211
-----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 69 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| EMP | 1 | 69 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | EMP_IDX | 1 | | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("EMPLOYEE_ID"=100) <<- Id 2: emp_idx 인덱스에서 100번의 rowid를 찾음select * from hr.emp where department_id = 20;
Full Table Scan
HR@ora19c> select * from hr.emp where department_id = 20;
Execution Plan
----------------------------------------------------------
Plan hash value: 3956160932
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 10 | 690 | 3 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| EMP | 10 | 690 | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("DEPARTMENT_ID"=20)hr.emp_dept_idx nonunique 인덱스 생성
HR@ora19c> create index hr.emp_dept_idx on hr.emp(department_id);
Index created.
HR@ora19c> select ix.index_name, ix.uniqueness, ic.column_name
from user_indexes ix, user_ind_columns ic
where ix.index_name = ic.index_name
and ix.table_name = 'EMP'; 2 3 4
INDEX_NAME UNIQUENES COLUMN_NAME
------------------------------ --------- ------------------------------
EMP_IDX NONUNIQUE EMPLOYEE_ID
EMP_DEPT_IDX NONUNIQUE DEPARTMENT_IDIndex Range Scan
HR@ora19c> set autotrace traceonly exp
HR@ora19c> select * from hr.emp where department_id = 20;
Execution Plan
----------------------------------------------------------
Plan hash value: 3572739823
----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 10 | 690 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| EMP | 10 | 690 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | EMP_DEPT_IDX | 10 | | 1 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("DEPARTMENT_ID"=20)인덱스 컬럼 가공 주의
HR@ora19c> select * from hr.emp where to_number(department_id) = 20;
Execution Plan
----------------------------------------------------------
Plan hash value: 3956160932
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 10 | 690 | 3 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| EMP | 10 | 690 | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter(TO_NUMBER(TO_CHAR("DEPARTMENT_ID"))=20)- 인덱스가 걸려 있는 컬럼을 가공하면 인덱스 스캔 불가 → Table Full Scan 발생
인덱스는 null에 대한 rowid를 저장하지 않음
HR@ora19c> select * from hr.emp where department_id is null;
Execution Plan
----------------------------------------------------------
Plan hash value: 3956160932
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 69 | 3 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| EMP | 1 | 69 | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("DEPARTMENT_ID" IS NULL)Full Table Scan Hint
HR@ora19c> select /*+ full(e) */ * from hr.emp e where employee_id = 100;
Execution Plan
----------------------------------------------------------
Plan hash value: 3956160932
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 69 | 3 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| EMP | 1 | 69 | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("EMPLOYEE_ID"=100)Index Scan Hint
HR@ora19c> select /*+ index(e emp_idx) */ * from hr.emp e where employee_id = 100;
Execution Plan
----------------------------------------------------------
Plan hash value: 3589413211
-----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 69 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| EMP | 1 | 69 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | EMP_IDX | 1 | | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("EMPLOYEE_ID"=100)Index Ragne Scan Hint
HR@ora19c> select /*+ index_rs(e emp_idx) */ * from hr.emp e where employee_id = 100;
Execution Plan
----------------------------------------------------------
Plan hash value: 3589413211
-----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 69 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| EMP | 1 | 69 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | EMP_IDX | 1 | | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("EMPLOYEE_ID"=100)Index Unique Scan
- 컬럼에 유일한 값으로 인덱스가 생성된 경우
- 비교 연산자 = 사용할 때만 사용
- unique index라고 하더라도 범위 스캔을 수행할 경우 index range scan으로 수행됨
Unique Index 생성
HR@ora19c> set autotrace off
HR@ora19c> drop index hr.emp_idx;
Index dropped.
# 유니크 인덱스 생성
HR@ora19c> create unique index hr.emp_idx on hr.emp(employee_id) tablespace users;
Index created.
# 인덱스 정보 조회
HR@ora19c> select ix.index_name, ix.uniqueness, ic.column_name
from user_indexes ix, user_ind_columns ic
where ix.index_name = ic.index_name
and ix.table_name = 'EMP'; 2 3 4
INDEX_NAME UNIQUENES COLUMN_NAME
------------------------------ --------- ------------------------------
EMP_IDX UNIQUE EMPLOYEE_ID
EMP_DEPT_IDX NONUNIQUE DEPARTMENT_ID
# 제약 조건 정보 조회
HR@ora19c> select c.column_name, u.constraint_name, u.constraint_type,u.search_condition,u.index_name
from user_constraints u, user_cons_columns c
where u.constraint_name = c.constraint_name
and u.table_name = 'EMP'; 2 3 4
COLUMN_NAME CONSTRAINT_NAME C SEARCH_CONDITION INDEX_NAME
------------------------------ ------------------------------ - ------------------------------ ------------------------------
LAST_NAME SYS_C007866 C "LAST_NAME" IS NOT NULL
EMAIL SYS_C007867 C "EMAIL" IS NOT NULL
HIRE_DATE SYS_C007868 C "HIRE_DATE" IS NOT NULL
JOB_ID SYS_C007869 C "JOB_ID" IS NOT NULLPK 제약 조건 추가
# emp_idx 유니크 인덱스를 사용하여 pk 생성
HR@ora19c> alter table hr.emp add constraint emp_id_pk primary key(employee_id) using index hr.emp_idx;
Table altered.
HR@ora19c> select c.column_name, u.constraint_name, u.constraint_type,u.search_condition,u.index_name
from user_constraints u, user_cons_columns c
where u.constraint_name = c.constraint_name
and u.table_name = 'EMP'; 2 3 4
COLUMN_NAME CONSTRAINT_NAME C SEARCH_CONDITION INDEX_NAME
------------------------------ ------------------------------ - ------------------------------ ------------------------------
LAST_NAME SYS_C007866 C "LAST_NAME" IS NOT NULL
EMAIL SYS_C007867 C "EMAIL" IS NOT NULL
HIRE_DATE SYS_C007868 C "HIRE_DATE" IS NOT NULL
JOB_ID SYS_C007869 C "JOB_ID" IS NOT NULL
EMPLOYEE_ID EMP_ID_PK P EMP_IDX- 제약 조건 이름과 인덱스 이름을 분리해야 하는 경우 유니크 인덱스를 먼저 생성 후 유니크 인덱스를 사용하여 PK를 생성함
autotrace
HR@ora19c> set autotrace traceonly exp
HR@ora19c> select * from hr.emp where employee_id = 100;
Execution Plan
----------------------------------------------------------
Plan hash value: 2466118986
---------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 69 | 1 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 69 | 1 (0)| 00:00:01 |
|* 2 | INDEX UNIQUE SCAN | EMP_IDX | 1 | | 0 (0)| 00:00:01 |
---------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("EMPLOYEE_ID"=100)INLIST Iterator
HR@ora19c> select * from hr.emp where employee_id in (100, 101);
Execution Plan
----------------------------------------------------------
Plan hash value: 1651504986
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2 | 138 | 2 (0)| 00:00:01 |
| 1 | INLIST ITERATOR | | | | | |
| 2 | TABLE ACCESS BY INDEX ROWID| EMP | 2 | 138 | 2 (0)| 00:00:01 |
|* 3 | INDEX UNIQUE SCAN | EMP_IDX | 2 | | 1 (0)| 00:00:01 |
----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("EMPLOYEE_ID"=100 OR "EMPLOYEE_ID"=101)- IN 연산자를 사용한 경우
INLIST ITERATOR연산 수행 - 내부적으로 아래 쿼리와 같이 변경
select * from hr.emp where employee_id = 100
union all
select * from hr.emp where employee_id = 101;- in list에 제공된 값만큼 root → branch → leaf 탐색을 반복 수행
- 조회하는 inlist 값이 불연속적으로 떨어져 있는 경우 사용
UNION
HR@ora19c> select * from hr.emp where employee_id = 100
union
select * from hr.emp where employee_id = 101; 2 3
Execution Plan
----------------------------------------------------------
Plan hash value: 28680880
-----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2 | 138 | 2 (0)| 00:00:01 |
| 1 | SORT UNIQUE | | 2 | 138 | 2 (0)| 00:00:01 |
| 2 | UNION-ALL | | | | | |
| 3 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 69 | 1 (0)| 00:00:01 |
|* 4 | INDEX UNIQUE SCAN | EMP_IDX | 1 | | 0 (0)| 00:00:01 |
| 5 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 69 | 1 (0)| 00:00:01 |
|* 6 | INDEX UNIQUE SCAN | EMP_IDX | 1 | | 0 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("EMPLOYEE_ID"=100)
6 - access("EMPLOYEE_ID"=101)- 집합 연산자로 연결된 두 쿼리 결과에 중복된 결과가 없음 → 중복 제거 작업 필요 없음
- UNION 연산자는 중복을 제거해야 하기 때문에
SORT UNIQUE연산을 수행하고 있음 → 비효율
UNION ALL
HR@ora19c> select * from hr.emp where employee_id = 100
union all
select * from hr.emp where employee_id = 101; 2 3
Execution Plan
----------------------------------------------------------
Plan hash value: 1345714510
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2 | 138 | 2 (0)| 00:00:01 |
| 1 | UNION-ALL | | | | | |
| 2 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 69 | 1 (0)| 00:00:01 |
|* 3 | INDEX UNIQUE SCAN | EMP_IDX | 1 | | 0 (0)| 00:00:01 |
| 4 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 69 | 1 (0)| 00:00:01 |
|* 5 | INDEX UNIQUE SCAN | EMP_IDX | 1 | | 0 (0)| 00:00:01 |
----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("EMPLOYEE_ID"=100)
5 - access("EMPLOYEE_ID"=101)- UNION ALL 연산자는 중복 제거가 필요 없으므로
SORT UNIQUE연산을 수행하지 않음
BETWEEN 연산자 사용
HR@ora19c> select * from hr.emp e where employee_id between 100 and 101;
Execution Plan
----------------------------------------------------------
Plan hash value: 3589413211
-----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2 | 138 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| EMP | 2 | 138 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | EMP_IDX | 2 | | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("EMPLOYEE_ID">=100 AND "EMPLOYEE_ID"<=101)- 조회하고자 하는 조건 컬럼의 값이 연속적인 경우 between이 나음 ← 수직적 탐색을 1번만 한 후 필요한 leaf block만 range scan하기 때문에
emp_name_idx 인덱스
HR@ora19c> set autot off
HR@ora19c> create index hr.emp_name_idx on hr.emp(last_name);
Index created.
HR@ora19c> select ix.index_name, ix.uniqueness, ic.column_name
from user_indexes ix, user_ind_columns ic
where ix.index_name = ic.index_name
and ix.table_name = 'EMP'; 2 3 4
INDEX_NAME UNIQUENES COLUMN_NAME
------------------------------ --------- ------------------------------
EMP_IDX UNIQUE EMPLOYEE_ID
EMP_DEPT_IDX NONUNIQUE DEPARTMENT_ID
EMP_NAME_IDX NONUNIQUE LAST_NAMEHR@ora19c> select * from hr.emp where last_name = 'King';
Execution Plan
----------------------------------------------------------
Plan hash value: 2092603121
----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 69 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| EMP | 1 | 69 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | EMP_NAME_IDX | 1 | | 1 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("LAST_NAME"='King')
emp_name_idx 인덱스 세그먼트에서 ‘King’ 조회
HR@ora19c> select last_name, rowid from hr.emp order by 1;
LAST_NAME ROWID
------------------------- ------------------
...
Kaufling AAAScmAAHAAAAHbAAW
Khoo AAAScmAAHAAAAHbAAP
**King AAAScmAAHAAAAHbAAA
King AAAScmAAHAAAAHbAA4**
Kochhar AAAScmAAHAAAAHbAAB
Kumar AAAScmAAHAAAAHbABJ
...
107 rows selected.- root → branch → leaf 안에 있는 첫 번째 King에 대한 rowid(AAAScmAAHAAAAHbAAA)를 찾아서 실제 블록으로 access
- 다시 leaf 안에서 두 번째 King에 대한 rowid(AAAScmAAHAAAAHbAA4)를 찾아서 실제 블록으로 access
- 다시 leaf 안에서 세 번째 King에 대한 rowid를 찾아봤지만 없어서 검색 종료
- active set 결과를 유저에게 전달
'Courses > 아이티윌 오라클 DBA 과정' 카테고리의 다른 글
| [아이티윌 오라클 DBA 과정 91기] 260204 TIL (0) | 2026.02.04 |
|---|---|
| [아이티윌 오라클 DBA 과정 91기] 260203 TIL (0) | 2026.02.03 |
| [아이티윌 오라클 DBA 과정 91기] 260130 TIL (0) | 2026.01.30 |
| [아이티윌 오라클 DBA 과정 91기] 260129 TIL (0) | 2026.01.30 |
| [아이티윌 오라클 DBA 과정 91기] 260128 TIL (0) | 2026.01.29 |