Analytics
2025. 10. 21. 18:08ㆍCERTIFICATES/AWS DEA-C01
AWS Glue
Glue란?
- 테이블 정의와 스키마를 자동으로 탐색하고 정의하는 서버리스 서비스임
- S3 데이터 레이크
- RDS
- Redshift
- DynamoDB
- 대부분의 다른 SQL 데이터베이스 지원함
- 사용자 정의 ETL 작업 지원함
- 트리거 기반, 일정 기반, 또는 온디맨드 방식으로 실행 가능함
- 완전 관리형 서비스임
Glue Crawler / Data Catalog
- Glue 크롤러는 S3에 있는 데이터를 스캔하여 스키마를 생성함
- 주기적으로 실행할 수 있음
- Glue Data Catalog를 채움
- 테이블 정의만 저장함
- 원본 데이터는 S3에 그대로 유지됨
- 한 번 카탈로그화되면 비정형 데이터를 마치 정형 데이터처럼 다룰 수 있음
- Redshift Spectrum
- Athena
- EMR
- QuickSight

Glue와 S3 파티션
- Glue 크롤러는 S3 데이터가 구성된 방식을 기반으로 파티션을 추출함
- S3 데이터 레이크에서 데이터를 어떻게 쿼리할 것인지 미리 고려해야 함
- 예시: 디바이스가 매시간 센서 데이터를 전송함
- 주로 시간 범위로 쿼리하는가?
- 그렇다면 버킷을 yyyy/mm/dd/device 형태로 구성해야 함
- 주로 디바이스 기준으로 쿼리하는가?
- 그렇다면 버킷을 device/yyyy/mm/dd 형태로 구성해야 함
Glue + Hive
- Hive는 EMR에서 SQL과 유사한 쿼리를 실행할 수 있게 함
- Glue Data Catalog는 Hive의 메타스토어 역할을 할 수 있음
- 또한 Hive 메타스토어를 Glue로 가져올 수도 있음
Glue ETL
- 자동 코드 생성 기능 제공함
- Scala 또는 Python 사용 가능함
- 암호화 지원함
- 서버 측 암호화(저장 시)
- SSL 암호화(전송 중)
- 이벤트 기반으로 동작할 수 있음
- 기본 Spark 작업의 성능을 높이기 위해 추가 DPU(Data Processing Units)를 프로비저닝할 수 있음
- 작업 메트릭을 활성화하면 필요한 최대 DPU 용량을 파악하는 데 도움이 됨
- Glue 콘솔(CloudWatch가 아님!)에서 최대 필요 실행기(executor)와 최대 할당 실행기를 비교하여 시각화할 수 있으며, ETL 데이터 이동량도 확인 가능함
- 오류는 CloudWatch에 보고됨
- SNS와 연동하여 알림을 받을 수도 있음
- 데이터를 변환, 정제, 보강하여 분석 전에 준비함
- Python 또는 Scala로 ETL 코드를 생성할 수 있으며, 생성된 코드를 수정 가능함
- 직접 작성한 Spark 또는 PySpark 스크립트를 제공할 수도 있음
- 대상은 S3, JDBC(RDS, Redshift), 또는 Glue Data Catalog가 될 수 있음
- 완전 관리형이며 비용 효율적임, 사용한 리소스에 대해서만 요금이 부과됨
- 작업은 서버리스 Spark 플랫폼에서 실행됨
- Glue Scheduler를 통해 작업을 예약할 수 있음
- Glue Triggers를 사용하여 이벤트 기반으로 작업 실행을 자동화할 수 있음
Glue ETL: DynamicFrame
- DynamicFrame은 DynamicRecord들의 집합
- DynamicRecord는 자체적으로 스키마를 가진 자기 기술적(self-describing) 구조임
- Spark의 DataFrame과 매우 유사하지만, ETL 기능이 더 추가되어 있음
- Scala와 Python API를 지원함


Glue ETL - 변환(Transformations)
- 기본 제공 변환 기능:
- DropFields, DropNullFields: null 필드를 제거함
- Filter: 레코드를 필터링할 함수를 지정함
- Join: 데이터를 보강하기 위해 조인 수행함
- Map: 필드 추가, 필드 삭제, 외부 조회 수행함
- 머신러닝 변환 기능:
- FindMatches ML: 공통된 고유 식별자가 없거나 필드가 정확히 일치하지 않아도 데이터셋에서 중복 또는 일치하는 레코드를 식별함
- 형식 변환 지원: CSV, JSON, Avro, Parquet, ORC, XML
- Apache Spark 변환 기능 지원(예: K-Means)
- Spark DataFrame과 Glue DynamicFrame 간 상호 변환 가능함
Glue ETL: ResolveChoice
- DynamicFrame 내의 모호한 데이터 유형 문제를 처리하고 새로운 DynamicFrame을 반환함
- 예를 들어, 동일한 이름을 가진 두 개의 필드가 존재하는 경우임
- make_cols: 각 타입에 대해 새로운 컬럼을 생성함 (예: price_double, price_string)
- cast: 모든 값을 지정된 타입으로 변환함
- make_struct: 각 데이터 타입을 포함하는 구조체(structure)를 생성함
- project: 모든 타입을 특정 타입으로 투영함 (예: project:string)
Glue ETL: Data Catalog 수정
- ETL 스크립트는 필요에 따라 스키마와 파티션을 업데이트할 수 있음
- 새로운 파티션 추가 방법
- 크롤러를 다시 실행하거나
- 스크립트에서 enableUpdateCatalog 및 partitionKeys 옵션을 사용함
- 테이블 스키마 업데이트 방법
- 크롤러를 다시 실행하거나
- 스크립트에서 enableUpdateCatalog 또는 updateBehavior를 사용함
- 새로운 테이블 생성
- setCatalogInfo와 함께 enableUpdateCatalog / updateBehavior를 사용함
- 제한 사항
- S3에서만 지원됨
- Json, CSV, Avro, Parquet 형식만 지원됨
- Parquet은 별도의 특수 코드가 필요함
- 중첩 스키마는 지원되지 않음
AWS Glue Development Endpoints
- 노트북 환경을 사용하여 ETL 스크립트를 개발함
- 이후 해당 스크립트를 실행하는 ETL 작업을 생성함 (Spark와 Glue를 사용함)
- 엔드포인트는 보안 그룹으로 제어되는 VPC 내에 있으며, 다음 방법으로 접속 가능함
- 로컬 머신의 Apache Zeppelin
- Glue 콘솔을 통해 EC2에서 실행되는 Zeppelin 노트북 서버
- SageMaker 노트북
- 터미널 창
- PyCharm Professional Edition
- Elastic IP를 사용하여 프라이빗 엔드포인트 주소에 접근할 수 있음
Glue 작업 실행
- 시간 기반 스케줄(cron 스타일) 지원함
- Job bookmark 기능
- 이전 작업 실행 상태를 유지함
- 기존 데이터를 재처리하지 않도록 방지함
- 스케줄 기반 재실행 시 새로운 데이터만 처리할 수 있게 함
- 다양한 형식의 S3 소스와 함께 동작함
- 관계형 데이터베이스와 JDBC를 통해 연동 가능함 (기본 키가 순차적일 경우)
- 새로운 행만 처리하며, 업데이트된 행은 처리하지 않음
- CloudWatch Events
- ETL 작업이 성공하거나 실패했을 때 Lambda 함수나 SNS 알림을 트리거함
- EC2 실행, Kinesis로 이벤트 전송, Step Functions 활성화 등의 동작을 수행할 수 있음
Glue 비용 모델
- 크롤러와 ETL 작업은 초 단위로 과금됨
- Glue Data Catalog에 저장 및 접근되는 처음 100만 개 객체는 무료임
- ETL 코드를 개발하기 위한 개발 엔드포인트는 분 단위로 과금됨
Glue 비권장 패턴(Anti-patterns)
- 여러 ETL 엔진을 동시에 사용하는 것은 비권장됨
- Glue ETL은 Spark 기반으로 동작함
- 다른 엔진(Hive, Pig 등)을 사용하고자 한다면 AWS Data Pipeline이나 EMR이 더 적합함
이제는 비권장 패턴이 아님: 스트리밍
- 2020년 4월부터 Glue ETL은 서버리스 스트리밍 ETL을 지원함
- Kinesis 또는 Kafka로부터 데이터를 수집함
- 데이터가 전송 중일 때 실시간으로 정제 및 변환함
- 결과를 S3 또는 다른 데이터 저장소에 저장함
- Apache Spark Structured Streaming 기반으로 동작함
AWS Glue Studio
- ETL 워크플로우를 위한 시각적 인터페이스 제공함
- 시각적 작업 편집기 제공함
- 복잡한 워크플로우를 위한 DAG(Directed Acyclic Graph) 생성 가능함
- 지원되는 소스: S3, Kinesis, Kafka, JDBC
- 데이터 변환, 샘플링, 조인 기능 제공함
- 대상(Target): S3 또는 Glue Data Catalog
- 파티셔닝 지원함
- 시각적 작업 대시보드 제공함
- 개요, 상태, 실행 시간 등을 확인할 수 있음
AWS Glue Data Quality
- 데이터 품질 규칙을 수동으로 생성하거나 자동으로 추천받을 수 있음
- Glue 작업에 통합되어 동작함
- Data Quality Definition Language(DQDL)를 사용함
- 규칙 결과를 기반으로 작업을 실패 처리할 수도 있고, 단순히 CloudWatch에 보고만 할 수도 있음
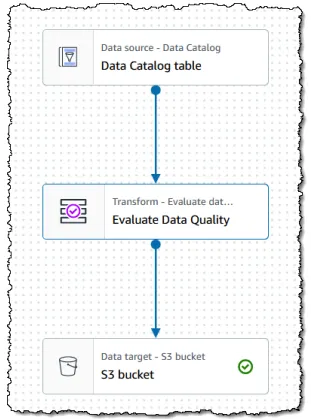
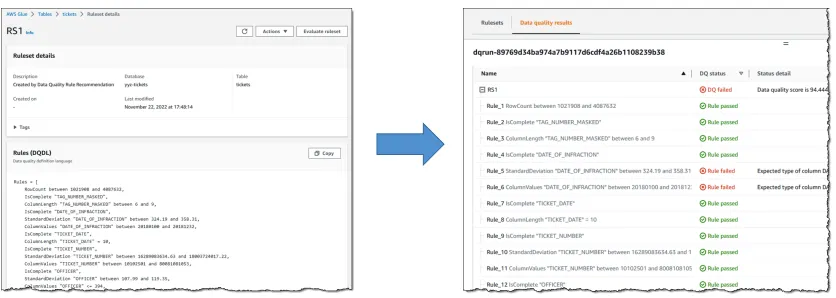
AWS Glue DataBrew
- 시각적 데이터 전처리 도구임
- 대규모 데이터셋을 사전에 처리하기 위한 UI를 제공함
- 입력 소스로 S3, 데이터 웨어하우스, 데이터베이스를 사용할 수 있음
- 출력 대상은 S3임
- 250개 이상의 사전 정의된 변환 기능을 제공함
- 변환 과정을 “레시피(recipes)”로 구성할 수 있으며, 이를 더 큰 프로젝트 내에서 작업(job)으로 저장 가능함
- 데이터 품질 규칙을 정의할 수 있음
- Redshift 및 Snowflake에서 사용자 정의 SQL을 사용하여 데이터셋을 생성할 수 있음
- 보안 기능
- KMS와 통합 가능함(단, 고객 관리형 키만 지원)
- 전송 중 SSL 암호화 지원
- IAM을 통해 사용자별 작업 권한을 제한할 수 있음
- CloudWatch 및 CloudTrail과 통합되어 모니터링 및 로깅 가능함

DataBrew에서 개인정보(PII) 처리 방법
- DataBrew 프로파일 작업에서 PII 통계 기능을 활성화하여 개인정보를 식별함
- 대체: REPLACE_WITH_RANDOM…
- 셔플링: SHUFFLE_ROWS
- 결정적 암호화: DETERMINISTIC_ENCRYPT
- 확률적 암호화: ENCRYPT
- 복호화: DECRYPT
- 값 제거 또는 삭제: DELETE
- 마스킹: MASK_CUSTOM, MASK_DATE, MASK_DELIMITER, MASK_RANGE
- 해싱: CRYPTOGRAPHIC_HASH
Glue Workflows
- 여러 작업(job)과 여러 크롤러(crawler)로 구성된 ETL 프로세스를 함께 실행하도록 설계함
- AWS Glue 블루프린트, 콘솔, 또는 API를 통해 생성할 수 있음
- Glue를 사용한 복잡한 ETL 작업의 오케스트레이션에만 사용됨

Glue Workflow 트리거(Triggers)
- 워크플로우 내 트리거는 작업(job)이나 크롤러(crawler)를 시작함
- 또는 작업이나 크롤러가 완료되었을 때 실행되도록 설정할 수도 있음
- 스케줄 기반 실행
- cron 표현식을 기반으로 실행
- 온디맨드(on demand) 실행 가능
- EventBridge 이벤트 기반 실행
- 단일 이벤트나 배치 이벤트가 발생할 때 시작 가능
- 예시: S3에 새로운 객체가 도착했을 때 실행
- 선택적 배치 조건 지원
- 배치 크기: 이벤트 개수 기준
- 배치 윈도우: 일정 시간(X초, 기본값 15분) 내 발생한 이벤트 기준
AWS Lake Formation
- 며칠 만에 안전한 데이터 레이크를 손쉽게 구축할 수 있게 해주는 서비스
- 데이터 적재 및 데이터 흐름 모니터링 기능 제공
- 파티션 설정 기능 제공
- 암호화 및 키 관리 기능 제공
- 변환 작업 정의 및 모니터링 기능 제공
- 접근 제어 기능 제공
- 감사(Auditing) 기능 제공
- Glue 위에 구축된 서비스
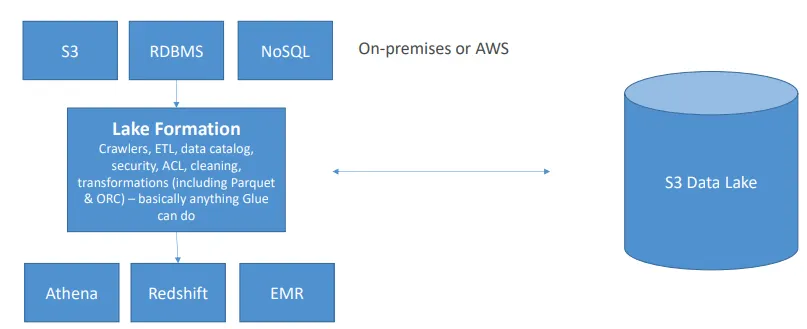
AWS Lake Formation: 요금
- Lake Formation 자체에는 별도의 비용이 없음
- 그러나 아래와 같은 기반 서비스에는 비용이 발생함
- Glue
- S3
- EMR
- Athena
- Redshift
AWS Lake Formation: 데이터 레이크 구축 절차
- 데이터 분석가를 위한 IAM 사용자 생성
- 데이터 소스와 연결하기 위한 AWS Glue 연결 생성
- 데이터 레이크용 S3 버킷 생성
- Lake Formation에 S3 경로를 등록하고 권한 부여
- 데이터 카탈로그용 데이터베이스를 Lake Formation에서 생성하고 권한 부여
- 워크플로우 생성을 위한 블루프린트 사용 (예: 데이터베이스 스냅샷)
- 워크플로우 실행
- 데이터를 조회해야 하는 사용자(Athena, Redshift Spectrum 등)에게 SELECT 권한 부여
AWS Lake Formation: 세부 사항
- 계정 간(Cross-account) Lake Formation 권한 설정 가능함
- 수신자는 데이터 레이크 관리자로 설정되어 있어야 함
- 조직 외부의 계정에 대해서는 AWS Resource Access Manager를 사용할 수 있음
- 계정 간 접근을 위해 IAM 권한이 필요함
- Lake Formation은 Athena나 Redshift 쿼리에서 매니페스트 파일을 지원하지 않음
- Lake Formation에서 암호화된 데이터 카탈로그를 사용하려면 KMS 암호화 키에 대한 IAM 권한이 필요함
- 블루프린트 및 워크플로우를 생성하려면 IAM 권한이 필요함
Lake Formation의 데이터 권한
- IAM 사용자나 역할, SAML, 또는 외부 AWS 계정과 연동할 수 있음
- 데이터베이스, 테이블, 컬럼에 정책 태그를 적용할 수 있음
- 테이블 또는 컬럼 단위로 세부 권한을 선택적으로 부여할 수 있음
Lake Formation의 데이터 필터
- 컬럼, 행, 또는 셀 단위의 보안을 지원함
- 테이블에 SELECT 권한을 부여할 때 적용됨
- 모든 컬럼 + 행 필터(Row filter) = 행 수준 보안
- 모든 행 + 특정 컬럼 지정 = 컬럼 수준 보안
- 특정 컬럼 + 특정 행 지정 = 셀 수준 보안
- 콘솔을 통해 필터를 생성할 수 있으며, 또는
CreateDataCellsFilterAPI를 통해 생성할 수도 있음
Amazon Athena
Athena란
- S3를 대상으로 하는 대화형 쿼리 서비스(SQL 기반)임
- 데이터를 로드할 필요 없이, S3에 있는 데이터를 그대로 쿼리함
- 내부적으로 Presto 엔진을 사용함
- 서버리스(Serverless) 서비스
- 다양한 데이터 형식을 지원함
- CSV, TSV (사람이 읽을 수 있는 형식)
- JSON (사람이 읽을 수 있는 형식)
- ORC (컬럼 기반, 분할 가능)
- Parquet (컬럼 기반, 분할 가능)
- Avro (분할 가능)
- Snappy, Zlib, LZO, Gzip 압축 지원
- 비정형, 반정형, 정형 데이터를 모두 지원함
예시
- 웹 로그에 대한 애드혹(ad-hoc) 쿼리 수행
- Redshift로 적재하기 전에 스테이징 데이터 검증 및 조회
- S3에 저장된 CloudTrail, CloudFront, VPC, ELB 등의 로그 분석
- Jupyter, Zeppelin, RStudio 노트북과의 통합 지원
- QuickSight와의 통합 지원
- ODBC / JDBC를 통한 다른 시각화 도구와의 연동 가능
Athena + Glue

Athena Workgroups
- 사용자, 팀, 애플리케이션, 워크로드를 Workgroup 단위로 구성할 수 있음
- Workgroup별로 쿼리 접근 제어 및 비용 추적이 가능함
- IAM, CloudWatch, SNS와 통합됨
- 각 Workgroup은 다음과 같은 개별 설정을 가질 수 있음
- 쿼리 이력(Query history)
- 데이터 한도(Data limits): Workgroup별로 쿼리가 스캔할 수 있는 데이터 양을 제한 가능함
- IAM 정책(IAM policies)
- 암호화 설정(Encryption settings)
Athena 비용 모델
- 사용량 기반 과금(pay-as-you-go) 방식임
- 스캔한 데이터 1TB당 5달러 부과됨
- 성공하거나 취소된 쿼리는 과금되지만, 실패한 쿼리는 과금되지 않음
- DDL 문(CREATE, ALTER, DROP 등)은 과금되지 않음
- 컬럼 기반 포맷(ORC, Parquet)을 사용하면 비용을 크게 절감할 수 있음
- 약 30~90%의 비용 절감 가능하며 성능도 향상됨
- Glue와 S3는 각각 별도의 과금이 적용됨
Athena 보안(Security)
- 접근 제어(Access control)
- IAM, ACL, S3 버킷 정책을 통해 제어함
- 기본 제공 정책: AmazonAthenaFullAccess, AWSQuicksightAthenaAccess
- S3 스테이징 디렉터리에 저장되는 쿼리 결과는 저장 시 암호화됨
- S3 관리형 키를 사용하는 서버 측 암호화(SSE-S3)
- KMS 키를 사용하는 서버 측 암호화(SSE-KMS)
- KMS 키를 사용하는 클라이언트 측 암호화(CSE-KMS)
- S3 버킷 정책을 통해 교차 계정(Cross-account) 접근 허용 가능함
- 전송 중 데이터는 TLS(Transport Layer Security)를 통해 암호화됨 (Athena와 S3 간 통신 구간)
Athena 비권장 패턴(Anti-patterns)
- 고정 형식의 리포트나 시각화 작업에는 부적합함
- 이러한 용도에는 QuickSight를 사용하는 것이 더 적합함
- ETL 작업 수행에는 적합하지 않음
- 대신 AWS Glue를 사용하는 것이 바람직함
Athena: 성능 최적화
- 컬럼 기반 포맷(ORC, Parquet)을 사용함
- 작은 파일이 많은 것보다, 큰 파일 소수가 더 좋은 성능을 보임
- 파티션을 사용함
- 나중에 파티션을 추가하는 경우,
MSCK REPAIR TABLE명령어를 사용함
- 나중에 파티션을 추가하는 경우,
Athena의 ACID 트랜잭션
- Apache Iceberg 기반으로 동작함
- CREATE TABLE 명령어에 ‘table_type’ = ‘ICEBERG’를 추가하면 됨
- 여러 사용자가 동시에 접근하더라도 안전하게 행 단위(row-level) 수정 가능함
- EMR, Spark 등 Iceberg 테이블 형식을 지원하는 모든 서비스와 호환됨
- 별도의 사용자 정의 레코드 잠금(record locking) 로직이 필요하지 않음
- 타임 트래블(Time travel) 기능 지원
- 최근 삭제된 데이터를 SELECT 문으로 복구할 수 있음
- Lake Formation의 관리형 테이블(Governed Table)은 Athena에서 ACID 기능을 제공하는 또 다른 방법임
- 주기적인 컴팩션(compaction)을 수행하면 성능을 지속적으로 유지할 수 있음
Athena의 AWS Glue Data Catalog 세분화된 접근 제어(Fine-Grained Access)
- IAM 기반의 데이터베이스 및 테이블 수준 보안을 지원함
- Lake Formation의 데이터 필터보다 더 광범위한 접근 제어 제공함
- 특정 테이블 버전에 대한 접근 제한은 불가능함
- 최소한, 각 리전에 있는 데이터베이스와 Glue Data Catalog에 접근할 수 있도록 권한을 부여하는 IAM 정책이 필요함

- 다음과 같은 작업들에 대한 접근을 제한하는 정책을 설정할 수 있음
- ALTER 또는 CREATE DATABASE
- CREATE TABLE
- DROP DATABASE 또는 DROP TABLE
- MSCK REPAIR TABLE
- SHOW DATABASES 또는 SHOW TABLES
- 이러한 작업들을 IAM 액션에 매핑하여 제어하면 됨
- 예시: DROP TABLE 작업을 제한하려면 해당 IAM 액션에 대한 권한을 명시적으로 제어해야 함
- 더 많은 예시는 아래 공식 문서에서 확인 가능
https://docs.aws.amazon.com/athena/latest/ug/fine-grained-access-to-glue-resources.html

Iceberg란?
- Apache Iceberg는 데이터 레이크용 테이블 포맷임
- 페타바이트(PB) 규모 데이터를 처리할 수 있음
- Netflix에서 처음 개발됨
- ACID 준수
- 데이터 추가, 삭제, 수정에 대해 트랜잭션 일관성을 보장함
- GDPR 준수를 위한 행 단위(row-level) 업데이트 및 삭제 지원함
- 스키마 진화(Schema Evolution)
- 데이터가 변화하더라도 안전하게 테이블 스키마를 업데이트할 수 있음
- 숨겨진 파티셔닝(Hidden Partitioning)
- 파티션 구조 변경 및 데이터 볼륨 확장이 가능함
- 타임 트래블(Time Travel)
- 과거 데이터를 쿼리하고, 업데이트 간의 변경 사항을 검증하며, 쉽게 롤백할 수 있음
- 효율적인 메타데이터 관리
- Spark, Flink, Trino, Presto, Hive와 호환됨
- AWS Glue, EMR, Athena와 통합되어 동작함
Iceberg + AWS Glue / S3
- Glue는 Iceberg의 테이블 메타데이터 소스로 Hive를 대체할 수 있음
- Iceberg의 API는 메타데이터 처리를 위해 Glue 카탈로그와 통신함
- Iceberg는 Amazon S3에 파일을 저장하고 조회함
- 일반적으로 Parquet 형식을 사용함
- Spark와 Flink는 Iceberg API 위에서 동작할 수 있음
- Athena 또한 Iceberg를 통해 ACID 트랜잭션을 지원함
- 즉, Athena의 ACID 기능은 Iceberg의 ACID 준수 기능을 기반으로 구현된 것임
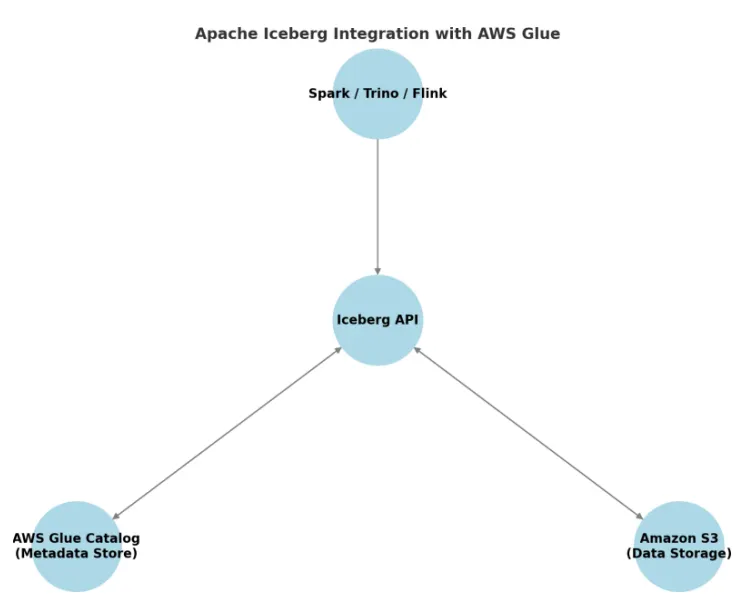
Glue Data Catalog을 Iceberg로 마이그레이션하기
- Glue Data Catalog은 Iceberg API와 호환되도록 설정되어야 함
- 설정이 완료되면 Athena에서 ACID 트랜잭션 기능을 사용할 수 있음
- 마이그레이션의 주요 목적:
- 규정 준수(Compliance): 테이블의 오래된 버전을 만료시키거나 감사 로그를 유지하기 위함
- 타임 트래블 쿼리를 활용한 과거 데이터 리포팅
- 다수의 데이터 생산자와 소비자가 동시에 존재하는 데이터 레이크 환경 지원
- 일관성(Consistency) 확보 필요
- 인플레이스(In-Place) 마이그레이션
- 기존 데이터 파일은 그대로 두고 Iceberg 메타데이터만 생성함
- 스키마나 파티션 변경은 허용되지 않음
- 섀도(Shadow) 마이그레이션
- 데이터를 복사하여 새로운 Iceberg 테이블로 이동
- 추가 검증 절차 수행 가능
- 롤백 및 복구가 더 용이

CREATE TABLE AS SELECT
- Amazon Athena에서 자주 사용되는 구문이지만, 다른 데이터베이스에서도 동일하게 존재함
- 쿼리 결과로부터 새로운 테이블을 생성함 (CTAS, Create Table As Select)
- 다른 테이블의 부분 집합(subset)으로 새로운 테이블을 생성할 때 사용할 수 있음
- 또한 데이터를 새로운 기반 형식(예: Parquet, ORC 등)으로 변환하는 데에도 사용할 수 있음
- 즉, Athena에서 S3에 저장된 데이터를 변환하는 데 활용할 수 있는 유용한 방법임

Athena Federated Queries
- S3 이외의 데이터 소스에 대해서도 쿼리를 실행할 수 있음
- 데이터 소스 커넥터(Data source connector)가 소스와 Athena 간의 쿼리 변환 역할을 수행함
- 이러한 커넥터들은 Lambda 위에서 동작함
- 매우 다양한 커넥터가 제공됨
- CloudWatch
- DynamoDB
- DocumentDB
- RDS
- OpenSearch
- JDBC
- 사용자 정의 커넥터(Custom connectors)
- 그리고 다양한 서드파티 커넥터 지원: Cloudera, HBase, Kafka, Oracle, Snowflake, Teradata 등
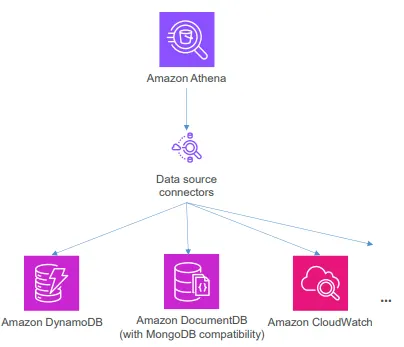
- Federated data sources에 대한 뷰(View)를 생성할 수 있음
- 이러한 뷰는 AWS Glue에 저장됨
- AWS Secrets Manager와 연동하여 인증 정보를 관리할 수 있음
- VPC 프라이빗 엔드포인트를 구성하면 보안 연결을 통해 접근 가능함
- 일부 커넥터는 AWS Glue와 통합되어 동작함
- Lake Formation을 통한 세분화된 접근 제어 가능함
- 지원되는 주요 데이터 소스: Redshift, BigQuery, DynamoDB, Snowflake, MySQL 등
- 적절한 권한이 부여되어 있다면 계정 간(Cross-account) 페더레이티드 쿼리도 가능함
- Passthrough Query 기능을 통해 데이터 소스의 고유한 쿼리 언어를 그대로 사용할 수 있음
- 일부 커넥터는 Spark의 데이터 소스로도 사용할 수 있음

Apache Spark
- 빅데이터 처리를 위한 분산 처리 프레임워크임
- 인메모리 캐싱 및 최적화된 쿼리 실행 기능을 제공함
- Java, Scala, Python, R 언어를 지원함
- 다양한 처리 방식 간 코드 재사용이 가능함
- 배치 처리
- 대화형 쿼리(Spark SQL)
- 실시간 분석
- 머신러닝(MLLib)
- 그래프 처리
- 스트리밍 처리
- Kinesis, Kafka와 통합되어 EMR에서 사용할 수 있음
- Spark는 OLTP 용도로 설계된 시스템이 아님

Spark의 동작 방식
- Spark 애플리케이션은 클러스터에서 독립적인 프로세스로 실행됨
- SparkContext(드라이버 프로그램)가 전체 작업을 조정함
- SparkContext는 클러스터 매니저를 통해 작업을 관리함
- Executor는 실제 연산을 수행하고 데이터를 저장함
- SparkContext는 애플리케이션 코드와 태스크를 Executor에게 전달함
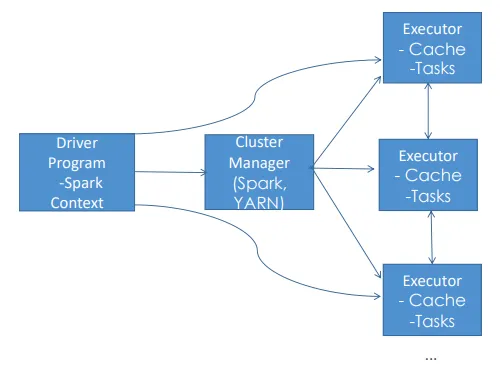
Spark 구성 요소

Spark Streaming
- 실시간 스트리밍 분석
- 구조화된 스트리밍 지원
- Twitter, Kafka, Flume, HDFS, ZeroMQ
Spark SQL
- MapReduce보다 최대 100배 빠름
- JDBC, ODBC, JSON, HDFS, ORC, Parquet, HiveQL 지원
MLLib
- 분류(Classification), 회귀(Regression), 클러스터링(Clustering), 협업 필터링(Collaborative Filtering), 패턴 마이닝(Pattern Mining)
- HDFS, HBase 등에서 데이터 읽기 가능
GraphX
- 그래프 처리(Graph Processing)
- ETL, 분석, 반복적 그래프 연산(Iterative Graph Computation)
- 현재는 거의 사용되지 않음
SPARK CORE
- 메모리 관리, 장애 복구, 스케줄링, 작업 분산 및 모니터링, 스토리지 상호작용 담당
- 지원 언어: Scala, Python, Java, R
지속적으로 증가하는 데이터셋을 실시간으로 처리하는 Spark Structured Streaming

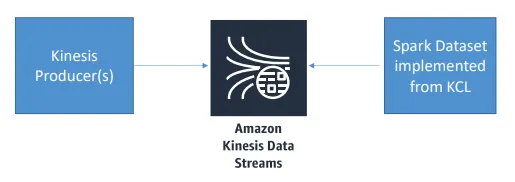
Spark Streaming + Kinesis
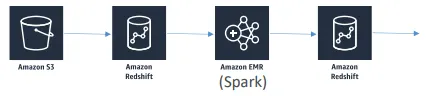
Spark + Redshift
- spark-redshift 패키지를 사용하면 Redshift의 데이터를 Spark 데이터셋으로 가져올 수 있음
- 이는 Spark SQL 데이터 소스임
- Spark를 활용한 ETL 작업에 유용함
Amazon Athena for Apache Spark
- Athena 콘솔 내에서 Spark를 사용한 Jupyter 노트북 실행이 가능함
- 노트북은 자동으로 또는 KMS를 통해 암호화될 수 있음
- 완전한 서버리스 환경임
- Athena SQL 대신 선택 가능한 대체 분석 엔진으로 사용할 수 있음
- Firecracker를 사용하여 Spark 리소스를 빠르게 프로비저닝함
- 프로그래밍 방식 API 및 CLI 접근도 가능함
- create-work-group, create-notebook, start-session, start-calculation-execution 등 명령어 제공
- 코디네이터(coordinator) 및 실행기(executor)의 DPU 크기를 조정할 수 있음
- 요금은 컴퓨팅 사용량 및 시간당 DPU 기준으로 과금됨
EMR(Elastic MapReduce)
EMR이란 무엇인가?
- Elastic MapReduce의 약자
- EC2 인스턴스에서 실행되는 관리형 Hadoop 프레임워크임
- Spark, HBase, Presto, Flink, Hive 등 다양한 빅데이터 엔진을 포함함
- EMR Notebooks 기능 제공함
- 여러 AWS 서비스와 통합 지점을 가짐
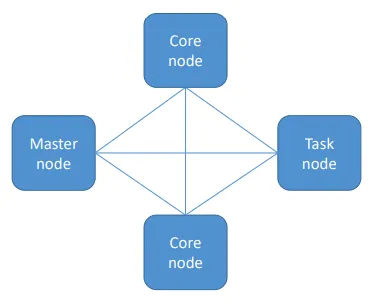
EMR 클러스터
- 마스터 노드(Master node): 클러스터를 관리함
- 작업 상태를 추적하고 클러스터의 상태를 모니터링함
- 단일 EC2 인스턴스로 구성됨 (단일 노드 클러스터로도 운영 가능함)
- “리더 노드(Leader node)”라고도 함
- 코어 노드(Core node): HDFS 데이터를 저장하고 작업을 실행함
- 확장(Scale up/down) 가능하지만 약간의 위험이 있음
- 다중 노드 클러스터에는 최소 하나 이상의 코어 노드가 필요함
- 태스크 노드(Task node): 작업만 실행하고 데이터를 저장하지 않음
- 선택적(Optional) 구성 요소임
- 제거 시 데이터 손실 위험이 없음
- 스팟 인스턴스를 사용하기에 적합함
EMR 사용 방식
- 단기 클러스터와 장기 클러스터로 구분됨
- 단기 클러스터는 모든 단계가 완료되면 자동으로 종료됨
- 데이터 적재, 처리, 저장 후 종료됨
- 비용 절감에 효과적임
- 장기 클러스터는 수동으로 종료해야 함
- 대규모 데이터셋을 주기적으로 처리하는 데이터 웨어하우스 형태로 운영됨
- 일시적인 처리 용량이 필요할 경우 스팟 인스턴스를 사용해 태스크 노드를 신속히 추가할 수 있음
- 장기 클러스터에서는 예약 인스턴스를 사용하여 비용을 절감할 수 있음
- 종료 보호는 기본적으로 활성화되어 있으며, 자동 종료는 기본적으로 비활성화되어 있음
- 프레임워크와 애플리케이션은 클러스터 생성 시 지정함
- 마스터 노드에 직접 연결하여 작업(Job)을 직접 실행할 수 있음
- 또는 콘솔을 통해 순차적인 단계(Step)를 제출할 수 있음
- S3나 HDFS의 데이터를 처리할 수 있음
- 처리 결과는 S3 또는 다른 저장소로 출력할 수 있음
- 한 번 정의된 단계(Step)는 콘솔을 통해 재실행할 수 있음
EMR / AWS 통합
- Amazon EC2: 클러스터를 구성하는 노드 인스턴스를 실행함
- Amazon VPC: 인스턴스를 실행할 가상 네트워크를 구성함
- Amazon S3: 입력 및 출력 데이터를 저장함
- Amazon CloudWatch: 클러스터 성능을 모니터링하고 알람을 설정함
- AWS IAM: 권한을 구성함
- AWS CloudTrail: 서비스에 대한 요청을 감사(audit)함
- AWS Data Pipeline: 클러스터의 스케줄링 및 실행을 관리함
EMR 스토리지
- HDFS (Hadoop Distributed File System)
- 클러스터 인스턴스 전체에 여러 복사본을 저장하여 중복성과 내결함성을 확보함
- 파일은 블록 단위로 저장됨 (기본 블록 크기 128MB)
- 일시적 저장소로, 클러스터가 종료되면 HDFS 데이터는 손실됨
- 하지만 중간 결과를 캐싱하거나 랜덤 I/O가 많은 워크로드에 유용함
- Hadoop은 HDFS에 저장된 데이터가 위치한 노드에서 직접 처리하도록 시도함
- EMRFS: S3를 HDFS처럼 접근할 수 있게 함
- 클러스터 종료 후에도 데이터를 지속적으로 보관할 수 있음
- EMRFS Consistent View 옵션을 통해 S3의 일관성을 보장할 수 있음
- DynamoDB를 사용하여 S3의 일관성 상태를 추적함
- DynamoDB의 읽기/쓰기 용량을 조정해야 할 수도 있음
- 2021년부터의 변경 사항: S3가 이제 강한 일관성을 기본적으로 지원함
- 로컬 파일 시스템
- 임시 데이터(버퍼, 캐시 등)에만 적합함
- HDFS용 EBS
- EBS 전용 인스턴스 타입(M4, C4 등)에서도 EMR을 사용할 수 있게 함
- 클러스터가 종료되면 삭제됨
- EBS 볼륨은 클러스터 생성 시에만 연결할 수 있음
- 수동으로 EBS 볼륨을 분리하면 EMR은 이를 장애로 간주하고 해당 볼륨을 교체함
EMR 보장 사항
- EMR은 시간 단위로 과금되며, EC2 요금이 별도로 부과됨
- 코어 노드가 장애가 발생하면 자동으로 새 노드를 프로비저닝함
- 태스크 노드는 실행 중에도 실시간으로 추가하거나 제거할 수 있음
- 처리 용량은 증가하지만 HDFS 용량은 증가하지 않음
- 실행 중인 클러스터의 코어 노드를 리사이즈할 수 있음
- 이 경우 처리 용량과 HDFS 용량이 모두 증가함
- 코어 노드 역시 추가하거나 제거할 수 있음
- 단, 코어 노드를 제거할 경우 데이터 손실 위험이 있음
EMR 관리형 스케일링
- EMR 자동 스케일링 (EMR Automatic Scaling)
- 기존의 방식임
- CloudWatch 지표를 기반으로 한 사용자 정의 스케일링 규칙 사용
- 인스턴스 그룹만 지원함
- EMR 관리형 스케일링
- 2020년에 도입됨
- 인스턴스 그룹과 인스턴스 플릿(instance fleets) 모두 지원함
- 동일한 클러스터 내에서 스팟(Spot), 온디맨드(On-demand), 세이빙 플랜(Savings Plan) 인스턴스를 혼합하여 스케일링 가능함
- Spark, Hive, YARN 워크로드에서 사용 가능함
- 스케일 업(Scale-up) 전략
- 먼저 코어 노드를 추가한 뒤, 태스크 노드를 추가함
- 설정된 최대 단위까지 확장함
- 스케일 다운(Scale-down) 전략
- 먼저 태스크 노드를 제거한 뒤, 코어 노드를 제거함
- 설정된 최소 제약 이하로는 축소하지 않음
- 스팟 인스턴스는 항상 온디맨드 인스턴스보다 먼저 제거됨
EMR Serverless
- EMR 릴리스와 런타임(Spark, Hive, Presto 등)을 선택함
- 쿼리나 스크립트를 Job Run 요청 형태로 제출함
- EMR이 기본 인프라 용량을 자동으로 관리함
- 단, 기본 워커 크기와 사전 초기화된 용량을 지정할 수 있음
- EMR이 작업(Job)에 필요한 리소스를 계산하고, 그에 맞게 워커를 자동으로 스케줄링함
- 하나의 리전 내에서 동작하며, 여러 가용 영역(AZ)에 걸쳐 확장 가능함
- 이게 왜 중요한가?
- 워크로드에 필요한 워커 수를 직접 추정할 필요가 없음
- 필요할 때 자동으로 프로비저닝되기 때문임
- 정말 서버리스(Serverless)인가?
- 엄밀히 말하면 완전한 서버리스는 아님
- 여전히 워커 노드의 구성과 크기를 고려해야 함
EMR Serverless 사용 방법
emr-serverless.amazonaws.com서비스에 대한 접근을 허용해야 함- 스크립트 및 데이터 입출력을 위한 S3 접근 권한을 부여해야 함
- SparkSQL을 사용할 경우 Glue 접근 권한이 필요함
- 암호화된 데이터를 사용하는 경우 KMS 키 접근 권한도 필요함

EMR Serverless 애플리케이션 수명주기
- 다음과 같은 API를 직접 호출해야 함
CreateApplicationStartApplicationStopApplicationDeleteApplication- 사용하지 않는 애플리케이션을 삭제하지 않으면 불필요한 요금이 발생할 수 있음

사전 초기화된 용량
- Spark는 드라이버(driver)와 실행기(executor)에 대해 요청된 메모리의 10%를 추가로 오버헤드로 사용함
- 따라서 작업(job)에서 요청한 메모리보다 최소 10% 이상 큰 초기 용량을 설정해야 함
EMR Serverless 보안
- 기본적으로 EMR과 동일한 보안 모델을 따름
- EMRFS 사용
- S3 저장 데이터 암호화(SSE 또는 CSE) 지원
- EMR 노드와 S3 간 통신은 TLS로 암호화됨
- S3 암호화 옵션
- SSE-S3
- SSE-KMS
- 로컬 디스크 암호화 지원
- Spark의 드라이버(driver)와 실행기(executor) 간 통신은 암호화됨
- Hive의 Glue Metastore와 EMR 간 통신은 TLS를 사용함
- S3 정책에서 HTTPS(TLS) 강제 적용 가능
- aws:SecureTransport 조건을 사용하여 HTTPS 연결만 허용함
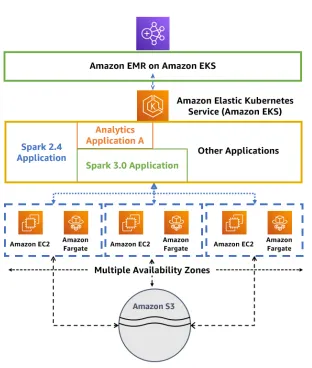
EMR on EKS
- 클러스터를 프로비저닝하지 않고 Elastic Kubernetes Service(EKS)에서 Spark 작업을 제출할 수 있음
- 완전 관리형 서비스임
- Kubernetes 상에서 Spark와 다른 애플리케이션이 리소스를 공유할 수 있음
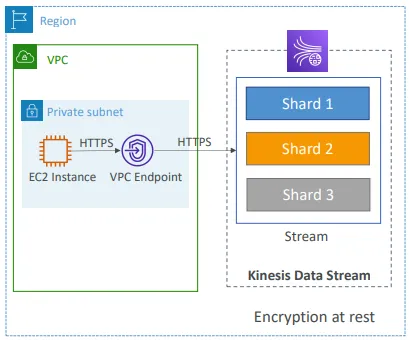
Kinesis Data Streams

- 데이터 보존 기간은 1일에서 365일까지 설정 가능함
- 데이터를 재처리(리플레이)할 수 있는 기능을 지원함
- 한 번 Kinesis에 삽입된 데이터는 삭제할 수 없음 (불변성, immutability)
- 동일한 파티션 키를 가진 데이터는 동일한 샤드(shard)로 전송됨 (순서 보장)
- 프로듀서(데이터 생산자): AWS SDK, Kinesis Producer Library(KPL), Kinesis Agent
- 컨슈머(데이터 소비자)
- 직접 구현하는 방식: Kinesis Client Library(KCL), AWS SDK
- 관리형 서비스: AWS Lambda, Kinesis Data Firehose, Kinesis Data Analytics
Kinesis Data Streams – 용량 모드(Capacity Modes)
- 프로비저닝 모드(Provisioned mode)
- 프로비저닝할 샤드 수를 직접 선택하며, 수동 또는 API를 통해 스케일 조정 가능함
- 각 샤드는 초당 1MB 입력(또는 초당 1000개의 레코드)을 처리함
- 각 샤드는 초당 2MB 출력 처리량을 가짐 (클래식 또는 향상된 팬아웃 소비자 기준)
- 시간당 프로비저닝된 샤드 단위로 요금이 부과됨
- 온디맨드 모드(On-demand mode)
- 용량을 사전에 프로비저닝하거나 관리할 필요가 없음
- 기본 용량은 초당 4MB 입력(또는 초당 4000개의 레코드)로 설정됨
- 최근 30일간 관찰된 최대 처리량을 기준으로 자동 확장됨
- 시간당 스트림 단위 및 데이터 입출력(GB 기준)으로 요금이 부과됨
Kinesis Data Streams 보안
- IAM 정책을 사용하여 접근 제어 및 권한 부여를 관리함
- HTTPS 엔드포인트를 통한 전송 중 암호화 지원함
- KMS를 사용한 저장 데이터 암호화 지원함
- 클라이언트 측에서 암호화 및 복호화를 직접 구현할 수도 있음 (복잡함)
- VPC 내에서 Kinesis에 접근할 수 있도록 VPC 엔드포인트 제공함
- CloudTrail을 통해 API 호출을 모니터링할 수 있음
Kinesis Producers
- Kinesis SDK
- Kinesis Producer Library(KPL)
- Kinesis Agent
- 서드파티 라이브러리: Spark, Log4J Appenders, Flume, Kafka Connect, NiFi 등

Kinesis Producer SDK - PutRecord(s)
- 사용되는 주요 API는 PutRecord(단일 레코드 전송)와 PutRecords(여러 레코드 배치 전송)임
- PutRecords는 배칭(Batching)을 통해 처리량을 높이고 HTTP 요청 수를 줄임
- 제한을 초과하면 ProvisionedThroughputExceeded 오류가 발생함
- AWS Mobile SDK(Android, iOS 등)에서도 사용 가능함
- 주요 사용 사례: 낮은 처리량, 높은 지연 허용, 단순한 API 호출, AWS Lambda 연동 등
- Kinesis Data Streams에 데이터를 전송하는 관리형 AWS 소스
- CloudWatch Logs
- AWS IoT
- Kinesis Data Analytics
AWS Kinesis API – 예외(Exceptions)
- ProvisionedThroughputExceeded 예외
- 샤드별 제한(MB/s 또는 TPS)을 초과하여 더 많은 데이터를 전송하려고 할 때 발생함
- 파티션 키가 비효율적이면 특정 파티션으로 데이터가 몰려 핫 샤드(hot shard)가 생길 수 있음
- 해결 방법
- 백오프(backoff)를 적용한 재시도(Retry) 수행
- 샤드 수를 늘려 스케일링 수행
- 균형 잡힌 데이터 분배를 위해 적절한 파티션 키를 사용함
Kinesis Producer Library (KPL)
- 사용하기 쉽고 고도로 설정 가능한 C++ / Java 라이브러리임
- 고성능, 장기 실행 프로듀서를 구축할 때 사용함
- 자동화된 재시도(retry) 메커니즘을 제공하며, 설정 가능함
- 동기 또는 비동기 API 제공 (비동기가 더 높은 성능 제공)
- CloudWatch로 메트릭을 전송하여 모니터링 가능함
- 배치 기능 (기본적으로 활성화됨)
- 처리량을 높이고 비용을 줄임
- 여러 레코드를 수집하여 동일한 PutRecords API 호출로 여러 샤드에 동시에 기록함
- 집계(Aggregation) 기능
- 약간의 지연이 증가하지만, 초당 1000 레코드 제한을 초과하는 다중 레코드 저장이 가능함
- 페이로드 크기를 늘려 처리량을 향상시키고 샤드당 1MB/s 한도를 최대한 활용함
- 압축은 사용자가 직접 구현해야 함
- KPL로 생성된 레코드는 KCL(Kinesis Client Library) 또는 전용 헬퍼 라이브러리를 통해 디코딩해야 함
Kinesis Producer Library (KPL) – 배치
RecordMaxBufferedTime설정값을 통해 배치 효율을 조정할 수 있음- 기본값은 100ms

Kinesis Producer Library (KPL) – 사용을 피해야 하는 경우
- KPL은 내부적으로 RecordMaxBufferedTime(사용자 설정 가능)만큼의 추가 처리 지연이 발생할 수 있음
- RecordMaxBufferedTime 값을 크게 설정할수록 배치 효율이 높아지고 전송 성능이 향상됨
- 이러한 추가 지연을 허용할 수 없는 애플리케이션의 경우, KPL 대신 AWS SDK를 직접 사용하는 것이 더 적합함
Kinesis Agent
- 로그 파일을 모니터링하고 해당 데이터를 Kinesis Data Streams로 전송함
- KPL 위에 구축된 Java 기반 에이전트임
- Linux 기반 서버 환경에 설치하여 사용함
- 주요 기능
- 여러 디렉터리에서 데이터를 읽어 여러 스트림으로 전송 가능함
- 디렉터리 또는 로그 파일 기준으로 라우팅 가능함
- 전송 전 데이터 전처리 가능 (예: 단일 라인 처리, CSV를 JSON으로 변환, 로그를 JSON으로 변환 등)
- 파일 로테이션, 체크포인팅, 장애 발생 시 재시도를 처리함
- CloudWatch로 메트릭을 전송하여 모니터링할 수 있음
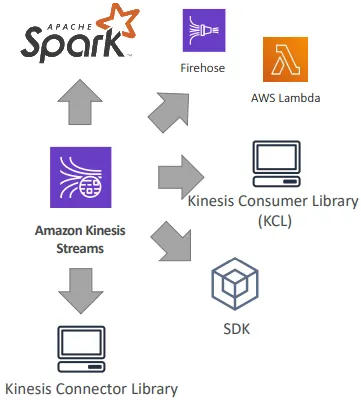
Kinesis Consumers - Classic
- Kinesis SDK
- Kinesis Client Library(KCL)
- Kinesis Connector Library
- 서드파티 라이브러리: Spark, Log4J Appenders, Flume, Kafka Connect 등
- Kinesis Firehose
- AWS Lambda
Kinesis Consumer SDK - GetRecords
- 클래식 Kinesis에서는 소비자(Consumer)가 샤드로부터 레코드를 폴링(poll)함
- 각 샤드는 총 2MB의 집계 처리량을 가짐
- GetRecords는 최대 10MB의 데이터를 반환한 다음 5초 동안 쓰로틀링되거나, 최대 10,000개의 레코드를 반환함
- 샤드당 초당 최대 5회의 GetRecords API 호출 가능함 (즉, 약 200ms 지연 발생)
- 동일한 샤드에서 5개의 소비자 애플리케이션이 데이터를 읽는 경우, 각 소비자는 초당 한 번만 폴링 가능하며 초당 약 400KB 미만의 데이터를 수신함

Kinesis Client Library (KCL)
- Java 중심 라이브러리이지만 다른 언어(Golang, Python, Ruby, Node, .NET 등)에서도 존재함
- KPL로 생성된 Kinesis에서 레코드를 읽음 (de-aggregation)
- 여러 소비자가 하나의 “그룹”에서 여러 샤드를 공유함, 샤드 탐색(shard discovery) 수행
- 진행 상태를 다시 이어서 수행하기 위한 체크포인팅(Checkpointing) 기능
- DynamoDB를 사용하여 조정(coordination) 및 체크포인팅 수행 (샤드당 하나의 행 사용)
- 충분한 WCU(Write Capacity Unit)와 RCU(Read Capacity Unit)를 프로비저닝해야 함
- 또는 DynamoDB 온디맨드(On-Demand) 모드를 사용할 수 있음
- 그렇지 않으면 DynamoDB가 KCL을 느리게 만들 수 있음
- 레코드 프로세서가 데이터를 처리함
- ExpiredIteratorException 발생 시 WCU를 증가시켜야 함
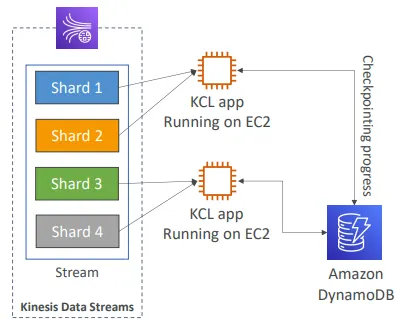
Kinesis Connector Library
- 오래된 Java 라이브러리(2016년)로, KCL 라이브러리를 기반으로 함
- 데이터를 다음 대상으로 쓸 수 있음
- Amazon S3
- DynamoDB
- Redshift
- OpenSearch
- 이러한 대상 중 일부는 Kinesis Firehose가, 나머지는 Lambda가 Connector Library를 대체함

AWS Lambda가 Kinesis를 소스로 사용하는 경우
- AWS Lambda는 Kinesis Data Streams로부터 레코드를 소스로 사용할 수 있음
- Lambda 소비자는 KPL로부터 온 레코드를 de-aggregate하기 위한 라이브러리를 가짐
- Lambda는 경량 ETL 처리를 위해 사용할 수 있음
- Amazon S3
- DynamoDB
- Redshift
- OpenSearch
- 원하는 모든 대상
- Lambda는 실시간으로 알림을 트리거하거나 이메일을 전송하는 데 사용할 수 있음
- Lambda는 설정 가능한 배치 크기를 가짐
Kinesis Enhanced Fan-Out
- 2018년 8월에 도입된 혁신적인 기능임
- KCL 2.0 및 AWS Lambda(2018년 11월)와 함께 동작함
- 각 소비자는 샤드당 2MB/s의 프로비저닝된 처리량을 가짐
- 즉, 소비자가 20명이라면 샤드당 총 40MB/s의 집계 처리량을 가지게 됨
- 더 이상 2MB/s 제한이 없음
- Enhanced Fan-Out은 HTTP/2를 통해 Kinesis가 데이터를 소비자에게 직접 푸시함
- 지연 시간을 약 70ms 수준으로 줄임

Enhanced Fan-Out vs Standard Consumers
- Standard Consumers
- 소비자 애플리케이션 수가 적음 (1개, 2개, 3개 정도)
- 약 200ms의 지연 시간을 허용할 수 있음
- 비용을 최소화함
- Enhanced Fan-Out Consumers
- 동일한 스트림에 여러 소비자 애플리케이션이 연결됨
- 약 70ms 수준의 낮은 지연 시간이 요구됨
- 비용이 더 높음 (자세한 내용은 Kinesis 요금 페이지 참조)
- 데이터 스트림당 최대 20개의 Enhanced Fan-Out 소비자 기본 제한이 있음
Kinesis Operations – 샤드 추가
- “샤드 분할(Shard Splitting)”이라고도 함
- 스트림의 용량을 확장하기 위해 사용할 수 있음 (샤드당 1MB/s 입력 처리량)
- 과도한 트래픽이 집중된 “핫 샤드(hot shard)”를 분할하는 데 사용할 수 있음
- 기존 샤드는 닫히며, 데이터 보존 기간이 만료되면 삭제됨

Kinesis Operations – 샤드 병합
- 스트림 용량을 줄여 비용을 절감할 수 있음
- 트래픽이 낮은 두 개의 샤드를 병합하는 데 사용할 수 있음
- 기존 샤드는 닫히며, 데이터 보존 기간이 만료되면 삭제됨

리샤딩 후 레코드 순서가 어긋나는 경우
- 리샤딩 후에는 자식 샤드에서 데이터를 읽을 수 있음
- 하지만 아직 읽지 않은 데이터가 부모 샤드에 남아 있을 수 있음
- 부모 샤드의 데이터를 모두 읽기 전에 자식 샤드에서 읽기 시작하면, 특정 해시 키에 대한 데이터가 순서가 어긋나게 읽힐 수 있음
- 따라서 리샤딩 이후에는 새로운 레코드가 더 이상 없을 때까지 부모 샤드에서 완전히 읽은 후에 자식 샤드를 읽어야 함
- 참고: Kinesis Client Library(KCL)는 이러한 리샤딩 후의 순서 제어 로직을 이미 내장하고 있음
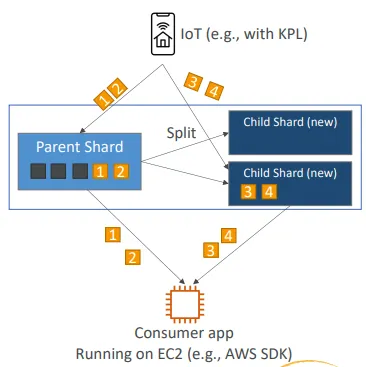
Kinesis Operations – 자동 스케일링 (Auto Scaling)
- 자동 스케일링(Auto Scaling)은 Kinesis의 기본 기능이 아님
- 샤드 수를 변경하기 위한 API 호출은 UpdateShardCount임
- AWS Lambda를 사용하여 자동 스케일링을 구현할 수 있음
- 참고: https://aws.amazon.com/blogs/big-data/scaling-amazon-kinesis-data-streams-with-aws-application-auto-scaling/

Kinesis 스케일링 제한사항
- 리샤딩은 병렬로 수행할 수 없으므로 사전에 용량을 계획해야 함
- 한 번에 하나의 리샤딩 작업만 수행할 수 있으며, 각 작업은 몇 초가 소요됨
- 예를 들어 1000개의 샤드를 2000개로 두 배 확장하려면 약 30,000초(약 8.3시간)가 걸림
- 다음과 같은 작업은 수행할 수 없음
- 24시간 기준으로 각 스트림당 최대 10배 이상 스케일링할 수 없음
- 현재 샤드 수의 두 배를 초과하여 확장할 수 없음
- 현재 샤드 수의 절반 이하로 축소할 수 없음
- 스트림 내 샤드 수를 10,000개 초과로 확장할 수 없음
- 10,000개 초과 샤드를 가진 스트림은, 리샤딩 결과가 10,000개 미만이 되지 않는 한 축소할 수 없음
- 계정당 설정된 샤드 제한을 초과하여 확장할 수 없음
Kinesis Data Streams – Producer 측 중복 처리
- 네트워크 타임아웃으로 인해 프로듀서의 재시도가 중복 레코드를 생성할 수 있음
- 두 레코드의 데이터가 동일하더라도, 각각 고유한 시퀀스 번호를 가짐
- 해결 방법: 데이터에 고유한 레코드 ID를 포함시켜 소비자 측에서 중복 제거 수행
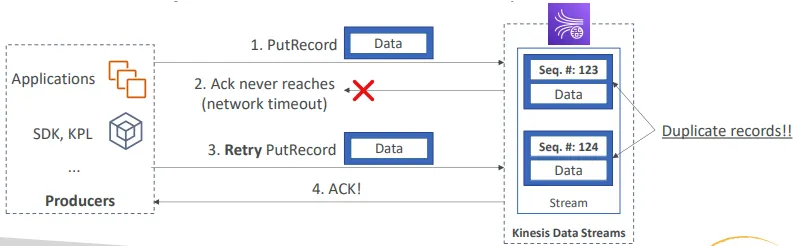
Kinesis Data Streams – Consumer 측 중복 처리
- 컨슈머의 재시도로 인해 애플리케이션이 동일한 데이터를 두 번 읽을 수 있음
- 컨슈머 재시도는 다음과 같은 상황에서 발생함
- 워커(Worker)가 예기치 않게 종료될 때
- 워커 인스턴스가 추가되거나 제거될 때
- 샤드가 병합되거나 분할될 때
- 애플리케이션이 배포될 때
- 해결 방법
- 컨슈머 애플리케이션을 멱등성을 갖도록 설계함
- 최종 저장소(Destination)가 중복 처리를 지원할 수 있다면, 해당 위치에서 중복 제거를 수행하는 것이 권장됨
- 참고: https://docs.aws.amazon.com/streams/latest/dev/kinesis-record-processor-duplicates.html
Kinesis 보안
- IAM 정책을 사용하여 접근 제어 및 권한 부여를 관리함
- HTTPS 엔드포인트를 사용하여 전송 중 암호화를 수행함
- KMS를 사용하여 저장 데이터 암호화를 수행함
- 클라이언트 측 암호화는 수동으로 직접 구현해야 함 (복잡함)
- VPC 내에서 Kinesis에 접근할 수 있도록 VPC 엔드포인트를 사용할 수 있음
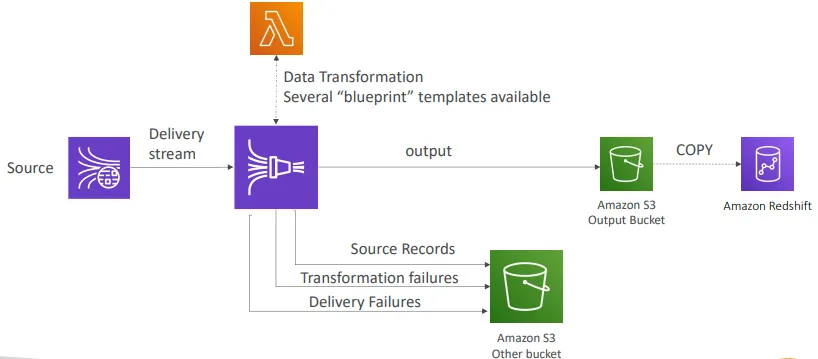
AWS Kinesis Data Firehose

- 완전 관리형 서비스로, 별도의 관리 작업이 필요 없음
- 거의 실시간으로 동작함 (시간 및 크기 기준 버퍼링, 필요 시 비활성화 가능)
- 데이터를 Redshift, Amazon S3, OpenSearch, Splunk로 로드할 수 있음
- 자동 스케일링 지원
- 다양한 데이터 형식 지원
- JSON 데이터를 Parquet 또는 ORC로 변환 가능함 (S3 대상일 경우에만 적용됨)
- AWS Lambda를 통해 데이터 변환 수행 가능함 (예: CSV → JSON)
- 대상이 Amazon S3일 경우 압축(GZIP, ZIP, SNAPPY) 지원함
- Redshift로 추가 로드되는 경우에는 GZIP만 지원됨
- Firehose를 통해 전송된 데이터의 양에 따라 요금이 부과됨
- Spark 및 KCL은 Kinesis Data Firehose(KDF)로부터 데이터를 읽을 수 없음
Kinesis Data Firehose Delivery Diagram
Firehose 버퍼 크기 설정
- Firehose는 레코드를 버퍼에 누적함
- 버퍼는 시간 및 크기 규칙에 따라 플러시(flush)됨
- 버퍼 크기 예시: 32MB — 해당 크기에 도달하면 버퍼가 플러시됨
- 버퍼 시간 예시: 2분 — 해당 시간이 지나면 버퍼가 플러시됨
- Firehose는 처리량을 높이기 위해 버퍼 크기를 자동으로 증가시킬 수 있음
- 처리량이 높을 경우 버퍼 크기 제한에 먼저 도달함
- 처리량이 낮을 경우 버퍼 시간 제한에 먼저 도달함
Kinesis Data Streams vs Firehose
- Streams
- 프로듀서와 컨슈머를 위한 사용자 정의 코드를 작성해야 함
- 실시간 처리 지원 (클래식 모드 약 200ms, Enhanced Fan-Out 약 70ms 지연)
- 스케일링을 직접 관리해야 함 (샤드 분할 및 병합)
- 데이터는 1일에서 최대 365일까지 저장 가능하며, 재처리(리플레이) 및 다중 소비자(Multi-consumer) 지원
- Lambda와 연동하여 예를 들어 OpenSearch로 데이터를 실시간 삽입할 수 있음
- Firehose
- 완전 관리형 서비스로, S3, Splunk, Redshift, OpenSearch로 데이터를 전송함
- Lambda를 사용한 서버리스 데이터 변환 지원
- 거의 실시간 처리(Near real time) 방식임
- 자동 스케일링 지원
- 데이터 저장 기능은 없음
Kinesis Data Stream 문제 해결 – 프로듀서 성능
- 쓰기 속도가 느린 경우
- 서비스 제한을 초과했을 수 있음
- 처리량 예외가 발생하는지 확인하고, 어떤 작업이 쓰로틀링(throttling)되고 있는지 점검해야 함
- 각 호출 유형별로 서로 다른 제한이 존재함
- 쓰기 및 읽기 작업은 샤드 단위 제한이 있음
- CreateStream, ListStreams, DescribeStreams 등의 다른 작업은 초당 5~20회의 스트림 단위 호출 제한이 있음
- 파티션 키를 잘 선택하여 데이터가 샤드 전체에 균등하게 분배되도록 해야 함
- 대규모 프로듀서
- 데이터를 배치 형태로 전송함
- Kinesis Producer Library(KPL), PutRecords(다중 레코드 전송), 또는 여러 레코드를 하나의 큰 파일로 집계하여 전송함
- 소규모 프로듀서( 예: 애플리케이션)
- PutRecords 또는 AWS Mobile SDK의 Kinesis Recorder를 사용함
기타 Kinesis Data Stream 프로듀서 문제
- 스트림이 500 또는 503 오류를 반환하는 경우
- AmazonKinesisException 오류율이 1%를 초과했음을 의미함
- 재시도 메커니즘을 구현해야 함
- Flink에서 Kinesis로의 연결 오류
- 네트워크 문제이거나 Flink 환경의 리소스 부족일 수 있음
- VPC 설정이 잘못되었을 가능성도 있음
- Flink에서 Kinesis로의 타임아웃 오류
- FlinkKinesisProducer의 RequestTimeout 및 #setQueueLimit 값을 조정해야 함
- 쓰로틀링(Throttling) 오류
- 향상된 모니터링을 사용하여 핫 샤드가 있는지 확인함 (샤드 레벨)
- 로그를 점검하여 미세한 처리량 급증(micro spikes)이나 불명확한 지표(metrics)가 제한을 초과하는지 확인함
- 무작위 파티션 키를 사용하거나 파티션 키 분포를 개선함
- 지수 백오프 전략을 적용함
- 속도 제한을 설정함
Kinesis Data Stream 문제 해결 – 컨슈머
- Kinesis Client Library(KCL)에서 레코드가 건너뛰어지는 경우
- processRecords 메서드에서 처리되지 않은 예외가 있는지 확인함
- 동일한 샤드의 레코드가 여러 프로세서에서 처리되는 경우
- 레코드 프로세서 워커의 failover로 인해 발생할 수 있음
- 장애 조치 시간을 조정함
- 종료 메서드에서 종료 이유가 “ZOMBIE”인 경우를 처리해야 함
- 읽기 속도가 느린 경우
- 샤드 수를 늘림
- 호출당 maxRecords 값이 너무 낮을 수 있음
- 코드 실행이 느릴 수 있으므로, 빈 프로세서와 비교하여 테스트함
- GetRecords가 빈 결과를 반환하는 경우
- 정상적인 동작이므로 GetRecords를 계속 호출하면 됨
- 샤드 이터레이터(Shard Iterator)가 예기치 않게 만료되는 경우
- DynamoDB의 샤드 테이블에 더 많은 쓰기 용량이 필요할 수 있음
- 레코드 처리가 지연되는 경우
- 문제 해결 중에는 데이터 보존 기간을 늘림
- 일반적으로 리소스가 부족한 것이 원인임
- GetRecords.IteratorAgeMilliseconds 및 MillisBehindLatest 메트릭을 모니터링
- Lambda 함수가 호출되지 않는 경우
- 실행 역할의 권한 문제일 수 있음
- 함수가 시간 초과되는 경우, 최대 실행 시간을 확인함
- 동시 실행 한도를 초과했을 수 있음
- IteratorAge 메트릭을 모니터링해야 하며, 문제가 있을 경우 해당 값이 증가함
- ReadProvisionedThroughputExceeded 예외 발생 시
- 쓰로틀링(Throttling) 문제임
- 스트림을 리샤딩함
- GetRecords 요청 크기를 줄임
- Enhanced Fan-Out을 사용함
- 재시도 및 지수 백오프를 적용함
- 지연 시간이 높음
- GetRecords.Latency와 IteratorAge로 모니터링함
- 샤드를 증가시킴
- 보존 기간을 증가시킴
- CPU와 메모리 사용률을 확인함(더 많은 메모리가 필요할 수 있음)
- 500 오류
- 프로듀서와 동일함 – 높은 오류율(>1%)을 의미함
- 재시도 메커니즘을 구현함
- 차단되거나 멈춘 KCL 애플리케이션
- processRecords 메서드를 최적화함
- maxLeasesPerWorker를 증가시킴
- KCL 디버그 로그를 활성화함
Kinesis Data Analytics / Managed Service for Apache Flink
Amazon Kinesis Data Analytics for SQL Application
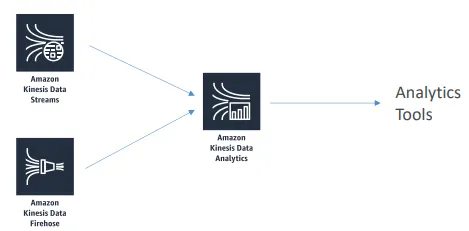

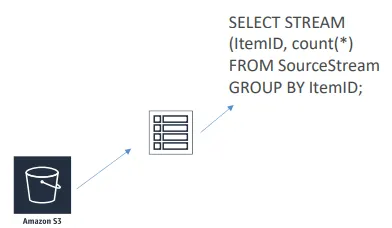
참조 테이블
- 데이터를 빠르게 조회하기 위한 저비용 조인 방식임
- 예: 우편번호에 연결된 도시 이름을 조회함
- 매핑 정보는 매우 저렴한 Amazon S3에 저장됨
- 쿼리 내에서 “JOIN” 명령을 사용하여 해당 데이터를 활용하면 됨
Kinesis Data Analytics + Lambda
- AWS Lambda 또한 데이터의 목적지로 사용할 수 있음
- 후처리에 매우 유연하게 활용 가능함
- 행(row) 집계 수행
- 다른 형식으로 변환
- 데이터 변환 및 정제
- 암호화 처리
- 다른 서비스 및 목적지와의 연동 가능
- S3, DynamoDB, Aurora, Redshift, SNS, SQS, CloudWatch 등과 연계 가능함
Managed Service for Apache Flink
- 이전 명칭은 Kinesis Data Analytics for Apache Flink 또는 Kinesis Data Analytics for Java였음
- Kinesis Data Analytics는 내부적으로 항상 Flink를 기반으로 동작했음
- 이제 Python과 Scala도 지원함
- Flink는 데이터 스트림을 처리하기 위한 프레임워크임
- MSAF(Managed Service for Apache Flink)는 Flink를 AWS 환경과 통합함
- SQL을 사용하는 대신, 직접 Flink 애플리케이션을 개발하여 S3를 통해 MSAF로 로드할 수 있음
- DataStream API 외에도 SQL 접근을 위한 Table API를 제공함
- 서버리스 방식으로 동작함

Apache Flink 기능
- 커넥터(Connectors)
- flink-connector-kinesis 라이브러리를 사용하면 Java 애플리케이션에서 데이터 스트림을 소비할 수 있음
- Flink에는 다양한 “Table API 커넥터” 라이브러리가 포함되어 있음
- Kafka, DynamoDB, Firehose, Kinesis, MongoDB, OpenSearch, JDBC 등 지원
- 사용자 정의 “sink” 커넥터를 통해 SDK가 제공되는 모든 시스템과 통신 가능함
- 예를 들어, Timestream 데이터베이스로 연결하는 sink를 직접 작성할 수 있음
- 연산자(Operators)
- 하나 이상의 DataStream을 새로운 DataStream으로 변환함
- Apache Spark의 변환 연산과 유사함
- Map, FlatMap, Filter, Reduce, Windows, Join 등의 연산 지원
- 물리적 파티셔닝 및 태스크 체이닝(Task chaining) 지원
일반적인 사용 사례
- 스트리밍 ETL
- 지속적인 메트릭 생성
- 실시간 분석
Kinesis Analytics
- 사용한 리소스에 대해서만 비용이 부과됨 (단, 저렴하지는 않음)
- 시간당 소비된 Kinesis Processing Unit(KPU) 단위로 과금됨
- 1 KPU = 1 vCPU + 4GB
- 서버리스 구조로 자동 확장됨
- 스트리밍 소스 및 목적지 접근은 IAM 권한을 통해 제어함
- 스키마 자동 탐지 기능을 제공함
RANDOM_CUT_FOREST
- 스트림 내의 숫자형 컬럼에서 이상값을 탐지하기 위한 SQL 함수임
- AWS에서 자체 연구 논문으로 발표한 기능이라 특히 자부심을 갖고 있음
- 데이터셋 내의 이상치를 식별하기 위한 새로운 방식으로, 탐지된 이상값을 다양한 방법으로 처리할 수 있음
- 예시: 뉴욕 마라톤 기간 동안 지하철 승객 수의 이상 패턴을 탐지함
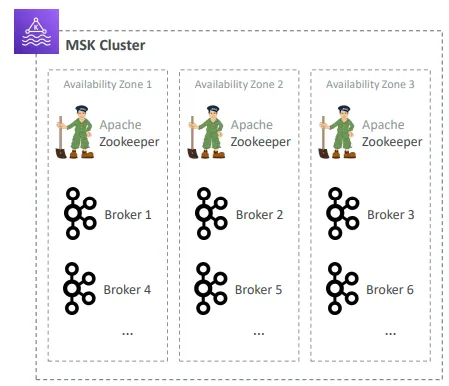
Amazon Managed Streaming for Apache Kafka (Amazon MSK)
- Kinesis의 대안으로 사용할 수 있는 서비스임
- AWS에서 완전관리형 Apache Kafka를 제공함
- 클러스터 생성, 업데이트, 삭제를 수행할 수 있음
- MSK가 Kafka 브로커 노드와 Zookeeper 노드를 자동으로 생성 및 관리함
- MSK 클러스터는 사용자의 VPC 내에 배포되며, 고가용성(HA)을 위해 최대 3개의 AZ에 걸쳐 구성 가능함
- 일반적인 Apache Kafka 장애 발생 시 자동 복구 기능을 제공함
- 데이터는 EBS 볼륨에 저장됨
- 데이터의 프로듀서(producer)와 컨슈머(consumer)를 구축할 수 있음
- 클러스터에 대한 사용자 정의 설정을 생성할 수 있음
- 기본 메시지 크기는 1MB임
- 사용자 정의 설정을 통해 대용량 메시지(예: 10MB)도 Kafka로 전송할 수 있음
Apache Kafka at a high level

MSK – 구성
- 가용 영역(AZ) 개수 선택 (3개 권장, 최소 2개 가능)
- 사용할 VPC와 서브넷 선택
- 브로커 인스턴스 유형 선택 (예: kafka.m5.large)
- AZ당 브로커 개수 설정 (추후 브로커 추가 가능)
- EBS 볼륨 크기 지정 (1GB ~ 16TB)
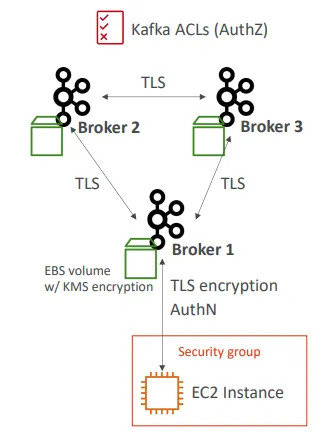
MSK – 보안
- 암호화:
- 브로커 간 통신 시 TLS를 이용한 전송 중 암호화 선택 가능
- 클라이언트와 브로커 간 통신 시 TLS 기반 전송 중 암호화 선택 가능
- EBS 볼륨의 데이터는 KMS를 이용해 저장 시 암호화 가능
- 네트워크 보안:
- Apache Kafka 클라이언트가 접근할 수 있도록 특정 보안 그룹을 허용해야 함
- 인증 및 인가(중요):
- 어떤 사용자가 어떤 토픽에 대해 읽기/쓰기 권한을 가질지 정의함
- Mutual TLS를 이용한 인증(AuthN) + Kafka ACL을 통한 인가(AuthZ)
- SASL/SCRAM 기반 인증(AuthN) + Kafka ACL 기반 인가(AuthZ)
- IAM Access Control을 이용해 인증과 인가(AuthN + AuthZ)를 통합적으로 수행함
MSK – 모니터링
- CloudWatch 메트릭스
- 기본 모니터링: 클러스터 및 브로커 단위 메트릭 제공
- 향상된 모니터링: 브로커 단위의 세부 메트릭 추가 제공
- 토픽 수준 모니터링: 토픽 단위의 상세 메트릭 제공
- Prometheus (오픈소스 모니터링)
- 브로커에서 포트를 열어 클러스터, 브로커, 토픽 수준의 메트릭을 내보낼 수 있음
- JMX Exporter(메트릭 수집용) 또는 Node Exporter(CPU 및 디스크 메트릭 수집용)를 설정하여 통합 모니터링 가능함
- 브로커 로그 전달
- CloudWatch Logs로 로그 전달 가능
- Amazon S3로 로그 전달 가능
- Kinesis Data Streams로 로그 스트리밍 전달 가능
MSK Connect
- AWS에서 제공하는 관리형 Kafka Connect 워커 서비스임
- 워커(Worker)에 대한 자동 스케일링 기능을 지원함
- 모든 Kafka Connect 커넥터를 플러그인 형태로 MSK Connect에 배포 가능함
- Amazon S3, Amazon Redshift, Amazon OpenSearch, Debezium 등 다양한 커넥터 사용 가능함
- 요금 예시: 워커당 시간당 0.11달러 과금됨

MSK Serverless
- 용량을 직접 관리하지 않고 Apache Kafka를 MSK에서 실행할 수 있음
- MSK가 컴퓨팅 및 스토리지 리소스를 자동으로 프로비저닝하고 스케일링함
- 사용자는 토픽과 파티션만 정의하면 바로 사용 가능함
- 보안: 모든 클러스터에 대해 IAM 기반 접근 제어 제공
- 요금 예시
- 클러스터당 시간당 0.75달러 (월 약 558달러)
- 파티션당 시간당 0.0015달러 (월 약 1.08달러)
- 스토리지 월 1GB당 0.10달러
- 데이터 수신 1GB당 0.10달러
- 데이터 송신 1GB당 0.05달러
Kinesis Data Streams vs Amazon MSK
Kinesis Data Streams
- 메시지 크기 제한: 최대 1MB
- Shard 기반 데이터 스트림 구조 사용
- Shard 분할 및 병합 기능 제공
- 전송 중 암호화: TLS 사용
- 저장 시 암호화: KMS 사용
- 보안: IAM 정책으로 인증(AuthN) 및 인가(AuthZ) 제어
Amazon MSK
- 기본 메시지 크기 1MB, 설정을 통해 확장 가능(예: 10MB)
- Kafka 토픽 기반 파티션 구조 사용
- 토픽에 파티션 추가는 가능하지만 기존 파티션 병합은 불가능
- 전송 중 암호화: PLAINTEXT 또는 TLS 선택 가능
- 저장 시 암호화: KMS 사용
- 보안:
- Mutual TLS 인증(AuthN) + Kafka ACL 인가(AuthZ)
- SASL/SCRAM 인증(AuthN) + Kafka ACL 인가(AuthZ)
- IAM Access Control을 통한 통합 인증 및 인가(AuthN + AuthZ)
Amazon Opensearch Service(구 Elasticsearch)
OpenSearch란?
- Elasticsearch와 Kibana에서 분기된 프로젝트임
- 검색 엔진
- 분석 도구
- 시각화 도구임 (Dashboards = Kibana)
- 데이터 파이프라인
- Kinesis가 Beats와 LogStash를 대체함
- 수평적으로 확장 가능
대시보드란?
Opensearch 애플리케이션
- 전문(full-text) 검색
- 로그 분석
- 애플리케이션 모니터링
- 보안 분석
- 클릭스트림 분석
OpenSearch 개념
Documents
- Document는 검색 대상이 되는 객체임
- 단순한 텍스트뿐 아니라 구조화된 JSON 데이터도 가능함
- 각 Document는 고유한 ID와 Type을 가짐
Types
- Type은 동일한 종류의 데이터를 나타내는 Document들이 공유하는 스키마와 매핑을 정의함
- 예: 로그 항목, 백과사전 기사 등
Indices
- Index는 특정 Type들의 집합에 포함된 모든 Document를 검색할 수 있도록 함
- 내부적으로 역색인(inverted index)을 포함하여, 전체 데이터를 한 번에 검색할 수 있게 함
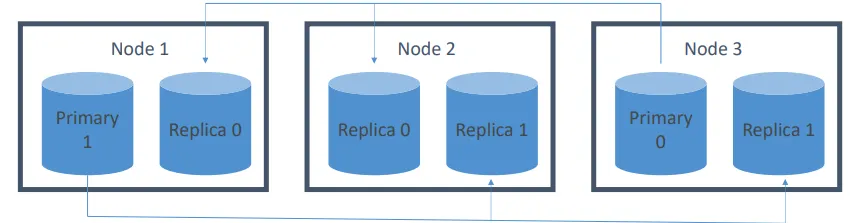
하나의 인덱스는 샤드로 분할됨
- Document는 특정 샤드로 해시됨
- 각 샤드는 클러스터 내의 서로 다른 노드에 위치할 수 있음
- 각 샤드는 자체적으로 완전한 Lucene 인덱스로 구성됨

중복성
- 이 인덱스는 두 개의 기본(primary) 샤드와 두 개의 복제(replica) 샤드를 가짐
- 애플리케이션은 요청을 노드들 간에 라운드 로빈 방식으로 분산시켜야 함
- 쓰기 요청은 기본 샤드로 라우팅된 후 복제됨
- 읽기 요청은 기본 샤드 또는 복제 샤드 중 어느 쪽으로든 라우팅됨
Amazon OpenSearch Service (Managed)
- 완전관리형 서비스이지만 서버리스는 아님
- 별도의 서버리스 옵션이 존재함
- 다운타임 없이 확장 또는 축소 가능함
- 단, 자동 확장은 아님
- 사용량 기반 요금제 적용
- 과금 항목: 인스턴스 사용 시간, 스토리지, 데이터 전송량
- 네트워크 격리 지원
- AWS 서비스 통합 가능
- S3 버킷 (Lambda를 통해 Kinesis로 연동)
- Kinesis Data Streams
- DynamoDB Streams
- CloudWatch / CloudTrail
- 가용 영역 인식 지원
Amazon OpenSearch 옵션
- 전용 마스터 노드 사용 가능
- 노드 개수와 인스턴스 유형 선택 가능
- 도메인 단위로 관리됨
- S3로 스냅샷 저장 가능
- 가용 영역 인식 지원
Cold / Warm / UltraWarm / Hot 스토리지
- 표준 데이터 노드는 Hot 스토리지를 사용함
- 인스턴스 스토리지 또는 EBS 볼륨 사용 / 가장 빠른 성능 제공
- UltraWarm(Warm) 스토리지는 S3와 캐싱을 함께 사용함
- 로그 데이터나 변경이 거의 없는 데이터에 적합함
- 성능은 느리지만 비용이 훨씬 저렴함
- 전용 마스터 노드가 필요함
- Cold 스토리지
- S3를 사용함
- 비용이 더 저렴함
- 오래된 데이터에 대한 주기적 조사나 포렌식 분석 용도로 적합함
- 전용 마스터 노드가 필요하며 UltraWarm이 활성화되어 있어야 함
- 데이터 노드에서 T2, T3 인스턴스 유형은 지원되지 않음
- 세분화된 액세스 제어를 사용하는 경우, OpenSearch Dashboards에서 사용자를 cold_manager 역할에 매핑해야 함
- 데이터는 서로 다른 스토리지 유형 간에 마이그레이션 가능함
Index State Management
- 인덱스 관리 정책을 자동화함
- 예시
- 일정 기간이 지난 후 오래된 인덱스를 삭제함
- 일정 기간이 지난 후 인덱스를 읽기 전용 상태로 전환함
- 시간이 지남에 따라 인덱스를 Hot → UltraWarm → Cold 스토리지로 이동함
- 시간이 지남에 따라 복제본 수를 줄임
- 인덱스 스냅샷을 자동화함
- ISM 정책은 30~48분마다 실행됨
- 모든 정책이 동시에 실행되지 않도록 랜덤 지터(jitter)가 적용됨
- 작업 완료 시 알림을 보낼 수도 있음
추가 인덱스 관리 기능
- 인덱스 롤업
- 오래된 데이터를 요약된 인덱스로 주기적으로 롤업함
- 스토리지 비용을 절감함
- 새로운 인덱스는 필드 수가 더 적거나 시간 단위가 더 넓을 수 있음
- 인덱스 변형
- 롤업과 유사하지만, 데이터를 다른 관점에서 분석하기 위한 새로운 뷰를 생성함
- 그룹화 및 집계를 수행함
Cross-cluster 복제
- 인덱스, 매핑, 메타데이터를 도메인 간에 복제함
- 장애 발생 시 고가용성을 보장함
- 지리적으로 데이터를 복제하여 지연 시간을 줄임
- Follower 인덱스가 Leader 인덱스로부터 데이터를 가져옴
- 세분화된 액세스 제어와 노드 간 암호화가 필요함
- Remote Reindex 기능을 사용하면 필요 시 한 클러스터에서 다른 클러스터로 인덱스를 복사할 수 있음
OpenSearch 안정성
- 전용 마스터 노드는 3개가 가장 이상적임
- “Split brain” 현상을 방지함
- 디스크 공간이 부족하지 않도록 주의해야 함
- 최소 스토리지 요구량은 대략 다음과 같음:
Source Data × (1 + Number of Replicas) × 1.45
- 최소 스토리지 요구량은 대략 다음과 같음:
- 샤드 수 결정
- (소스 데이터 + 확장 여유 공간) × (1 + 인덱싱 오버헤드) ÷ 원하는 샤드 크기
- 드물게 노드당 샤드 수를 제한해야 할 수도 있음
- 일반적으로 디스크 공간이 먼저 부족해짐
- 인스턴스 유형 선택 시 권장 사항
- 최소 3개 노드 필요
- 주로 스토리지 요구량에 따라 결정됨
- 예: m6g.large.search, i3.4xlarge.search, i3.16xlarge.search
Amazon OpenSearch 보안
- 리소스 기반 정책
- 아이덴티티 기반 정책
- IP 기반 정책
- 요청 서명
- VPC
- Cognito
Dashboards 보안
- Cognito
- 외부에서 VPC 내부로 접근하는 것은 어려움
- EC2에 Nginx 리버스 프록시를 구성하여 OpenSearch 도메인으로 포워딩함
- 포트 5601에 대해 SSH 터널을 사용할 수 있음
- VPC Direct Connect 사용 가능함
- VPN 사용 가능함

Amazon OpenSearch 비권장 패턴
- OLTP 용도로 사용하지 않음
- 트랜잭션 기능이 없음
- RDS 또는 DynamoDB 사용이 더 적합함
- 임시(Ad-hoc) 데이터 쿼리에는 적합하지 않음
- Athena 사용이 더 적합함
- OpenSearch는 기본적으로 검색과 분석에 사용되는 서비스임
Amazon OpenSearch 성능
- JVM 메모리 압력이 발생할 수 있는 경우
- 노드 간 샤드 분배가 불균형한 경우
- 클러스터 내 샤드 수가 너무 많은 경우
- JVMMemoryPressure 오류가 발생하면 샤드 수를 줄이면 성능이 향상될 수 있음
- 오래되거나 사용하지 않는 인덱스를 삭제해야 함
Amazon OpenSearch Serverless
- 온디맨드 자동 확장 지원함
- 프로비저닝된 도메인 대신 컬렉션(collection) 단위로 동작함
- 컬렉션 유형은 “Search” 또는 “Time Series”일 수 있음
- 항상 사용자의 KMS 키로 암호화됨
- 데이터 액세스 정책 적용 가능함
- 저장 시 암호화는 필수임
- 여러 컬렉션에 걸쳐 보안 정책을 구성할 수 있음
- 용량은 OpenSearch Compute Units(OCU) 단위로 측정됨
- 상한을 설정할 수 있으며, 하한은 인덱싱 2개, 검색 2개로 고정됨
Amazon QuickSight
QuickSight란 무엇인가?
- 빠르고 간편한 클라우드 기반 비즈니스 분석 서비스임
- 조직 내 모든 직원이 다음을 수행할 수 있게 함
- 시각화 생성
- 페이지가 매겨진 보고서 생성
- 임시 분석 수행
- 감지된 이상 징후에 대한 알림 수신
- 데이터로부터 빠르게 비즈니스 인사이트 획득
- 언제든지, 어떤 기기(브라우저, 모바일)에서도 가능함
- 서버리스임
QuickSight 데이터 소스
- Redshift
- Aurora / RDS
- Athena
- OpenSearch
- IoT Analytics
- EC2에 호스팅된 데이터베이스
- 파일(S3 또는 온프레미스)
- Excel
- CSV, TSV
- 일반 로그 형식 또는 확장 로그 형식
- 데이터 준비 과정에서 제한적인 ETL 수행 가능함
SPICE
- 데이터 세트는 SPICE로 가져옴
- 초고속 병렬 인메모리 계산 엔진임
- 컬럼 기반 저장 방식, 인메모리 구조, 머신 코드 생성을 사용함
- 대규모 데이터 세트에 대한 대화형 쿼리를 가속화함
- 사용자당 10GB의 SPICE 용량이 제공됨
- 고가용성과 내구성을 가짐
- 수십만 명의 사용자로 확장 가능함
- 직접 쿼리 모드(Athena 직접 조회)에서 시간 초과될 수 있는 대규모 쿼리를 가속화할 수 있음
- 그러나 데이터를 SPICE로 가져오는 데 30분 이상 걸리면 여전히 시간 초과됨
QuickSight 사용 사례
- 데이터의 대화형 임시 탐색 및 시각화
- 대시보드와 KPI 분석
- 다음과 같은 데이터의 분석 및 시각화
- S3에 저장된 로그
- 온프레미스 데이터베이스
- AWS(RDS, Redshift, Athena, S3)
- Salesforce와 같은 SaaS 애플리케이션
- 모든 JDBC/ODBC 데이터 소스
QuickSight 안티 패턴
- ETL
- QuickSight에서도 일부 변환은 가능하지만, ETL 작업에는 Glue를 사용하는 것이 더 적합함
QuickSight 보안
- 계정에 다중 인증(MFA) 적용
- VPC 연결 지원
- 데이터베이스 보안 그룹에 QuickSight의 IP 주소 범위를 추가해야 함
- 행 수준 보안 지원
- 2021년부터 열 수준 보안(Column-level security, CLS)도 지원됨 (엔터프라이즈 에디션 전용)
- 프라이빗 VPC 액세스 지원
- Elastic Network Interface, AWS Direct Connect 사용 가능함
- 리소스 접근
- QuickSight가 Athena, S3, 그리고 사용자의 S3 버킷을 사용할 수 있도록 권한이 부여되어야 함
- 이는 QuickSight 콘솔 내에서 관리할 수 있음 (Manage QuickSight / Security & Permissions)
- 데이터 접근
- QuickSight 사용자가 S3 내에서 접근할 수 있는 데이터를 제한하기 위해 IAM 정책을 생성할 수 있음
QuickSight + Redshift: 보안
- 기본적으로 QuickSight는 QuickSight가 실행 중인 리전과 동일한 리전에 저장된 데이터에만 접근할 수 있음
- 따라서 QuickSight가 한 리전에서 실행되고 Redshift가 다른 리전에 있을 경우 문제가 발생함
- 여러 리전에 걸쳐 작동하도록 구성된 VPC는 동작하지 않음
- 해결 방법: 해당 리전의 QuickSight 서버 IP 범위에서 접근을 허용하는 인바운드 규칙을 가진 새로운 보안 그룹을 생성해야 함
- 이러한 IP 범위는 다음 문서에 명시되어 있음 https://docs.aws.amazon.com/quicksight/latest/user/regions.html
QuickSight / Redshift / RDS 간 교차 리전 연결
- 엔터프라이즈 에디션을 사용하는 경우 가능한 방법
- VPC 내에 프라이빗 서브넷 생성
- Elastic Network Interface(ENI)를 사용하여 QuickSight를 해당 서브넷에 배치함
- 이 기능은 엔터프라이즈 에디션에서만 지원됨
- 또한 교차 계정 접근도 가능하게 함

- 이제 프라이빗 서브넷과 데이터를 포함한 다른 프라이빗 서브넷 간에 피어링 연결을 생성할 수 있음
- 이 방식은 교차 계정 접근에도 동일하게 적용됨

QuickSight / Redshift / RDS 간 교차 계정 연결
- 서브넷을 연결하기 위해 AWS Transit Gateway를 사용할 수 있음
- 단, 동일한 조직과 리전 내에 있어야 함
- 또는 서로 다른 리전에 있는 Transit Gateway 간 피어링을 설정할 수 있음
- 또는 AWS PrivateLink를 사용하여 연결할 수 있음
- 또는 VPC 공유(VPC sharing)를 통해 연결할 수 있음

QuickSight 사용자 관리
- 사용자는 IAM을 통해 정의하거나 이메일 등록을 통해 생성할 수 있음
- 엔터프라이즈 에디션에서는 Active Directory 커넥터 사용 가능함
- 모든 키는 AWS에서 관리하며, 사용자가 제공한 키는 사용할 수 없음
- 해당 기능은 엔터프라이즈 에디션에서만 제공됨
- 보안 접근 설정을 세부적으로 조정할 수 있음
QuickSight 요금
- 연간 구독 기준
- 스탠다드: 사용자당 월 $9
- 엔터프라이즈: 사용자당 월 $18
- QuickSight Q 포함 시: 사용자당 월 $28
- SPICE 용량이 10GB를 초과할 경우 추가 요금 발생
- 스탠다드: GB당 월 $0.25
- 엔터프라이즈: GB당 월 $0.38
- 월 단위 구독 기준
- 스탠다드: 사용자당 월 $12
- 엔터프라이즈: 사용자당 월 $24
- QuickSight Q 포함 시: 사용자당 월 $34
- 엔터프라이즈 에디션 기능
- 저장 데이터 암호화
- Microsoft Active Directory 통합
QuickSight 대시보드
- 분석 결과의 읽기 전용 스냅샷임
- QuickSight 접근 권한이 있는 사용자와 공유할 수 있음
- 임베디드 대시보드를 통해 더 넓은 범위로 공유 가능함
- 애플리케이션 내에 임베드할 수 있음
- Active Directory, Cognito, 또는 SSO로 인증 가능함
- QuickSight JavaScript SDK 또는 QuickSight API 사용 가능함
- 임베딩이 허용된 도메인을 화이트리스트로 지정해야 함
QuickSight 머신러닝 인사이트
- 머신러닝 기반 이상 탐지 기능 제공
- Random Cut Forest 알고리즘 사용
- 지표의 유의미한 변화에 가장 많이 기여한 주요 요인을 식별함
- 머신러닝 기반 예측 기능 제공
- 이 또한 Random Cut Forest를 사용함
- 계절성과 추세를 탐지함
- 이상치를 제외하고 누락된 값을 보정함
- 자동 내러티브(Autonarratives)
- 대시보드에 데이터의 스토리를 자동으로 추가함
- 인사이트 제안
- “Insights” 탭에서 즉시 사용할 수 있는 제안형 인사이트를 표시함
QuickSight 계산 필드
- 다른 필드를 기반으로 새로운 필드를 생성함
- 예를 들어, 이익률과 같은 값을 계산할 수 있음
- 수학 및 논리 연산자 지원
- /, *, AND, OR, NOT 등
- 조건 함수 지원
- If, else, not 등
- 날짜 함수 지원
- 날짜 오프셋, 포맷팅 등
- 수치 및 수학 함수 지원
- log, sqrt, round 등
- 문자열 함수 지원
- 테이블 계산 함수 지원
- 이동 평균, 최소/최대값 계산 등
- 집계 함수 지원
- avg, min, max, stddev 등
레벨 인식 계산(LAC)
- 계산의 세분화 수준을 제어함
- 이는 표시 수준에서 수행되는 집계와는 독립적으로, 그리고 그 이전 단계에서 계산될 수 있음
- LAC-A: 집계 함수를 의미함
- sum({Sales})는 표시된 열(Region, Country, Product)에 대해 집계를 수행함
- 하지만 다른 수준에서 집계하는 것도 가능함
- sum({Sales}, [{Country}])
- 이는 Country 단위로만 집계함
- Country가 시각화에 표시되지 않아도 작동함
- sum, count, percentile 등의 함수에 적용 가능함

레벨 인식 계산 – 윈도우(LAC-W)
- 윈도우 또는 파티션 단위로 집계를 수행함
- 특정 윈도우 범위 내에서 계산된 값이 각 행에 추가됨
- 주요 윈도우 함수에는 sumOver, maxOver, denseRank 등이 있음
- 아래 예시: 주문 금액(Order amount)은 sumOver({Sales}, [{Order ID}], PRE_AGG)로 정의됨
- 특정 윈도우 범위 내에서 계산된 값이 각 행에 추가됨
- PRE_AGG는 디스플레이 수준 집계가 이루어지기 전에 윈도우 함수를 적용함을 의미함
- PRE_FILTER는 디스플레이 수준 필터가 적용되기 전에 계산이 수행됨을 의미함
FLOAT vs FIXED 데이터 타입
- 계산 필드를 사용할 때 FIXED 타입은 정밀도 문제가 발생할 수 있음
- FIXED 타입은 소수점 이하 4자리까지만 처리함
- 반올림 및 계산 과정에서 정확도 손실이나 오버플로우 문제가 발생할 수 있음
- 더 높은 정밀도가 필요할 경우 FLOAT 데이터 타입을 사용해야 함
- FLOAT는 최대 16자리의 유효 숫자까지 정확도를 보장함
- 데이터 가져오기 시 반올림 오류를 방지함
- 계산 수행 시 정확도 손실을 방지함
'CERTIFICATES > AWS DEA-C01' 카테고리의 다른 글
| Security, Identity and Compliance (0) | 2025.10.21 |
|---|---|
| Application Integration (0) | 2025.10.21 |
| Container (0) | 2025.10.14 |
| Compute (0) | 2025.10.14 |
| Migration and Transfer (0) | 2025.10.14 |