251014 TIL
2025. 10. 14. 17:43ㆍCourses/아이티윌 오라클 DBA 과정
WordCloud
from matplotlib import pyplot
from wordcloud import WordCloud
text = ''
with open("res/이상한나라의앨리스.txt", "r", encoding="utf-8") as f:
text = f.read()
wc = WordCloud(
width=1200,
height=800,
scale=3.0
)
gen = wc.generate(text)
gen.words_
# 금지어 설정 모듈
from wordcloud import STOPWORDS
# 금지어 설정
# -> 금지어 : said, alice, Gutenberg
ignore = set(STOPWORDS)
ignore.add("said")
ignore.add("alice")
ignore.add("Gutenberg")
#WordCloud클래스의 객체 생성
wc = WordCloud(
width=1200,
height=800,
scale=2.0,
stopwords=ignore, #금지어
max_font_size=150, #최대 글자 크기
max_words=100 #최대 표시 단어수
)
gen = wc.generate(text)
pyplot.figure()
pyplot.imshow(gen, interpolation="bilinear")
pyplot.show()
pyplot.close()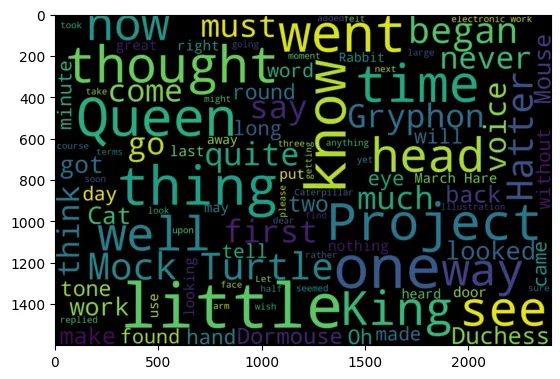
# 2) Word Cloud 배경 이미지
import numpy as np
from PIL import Image # 이미치 처리 모듈, 기본모듈이므로 따로 설치할 필요 없음
"""----------------------------------------------------------------------------------------
이미지 분석 및 처리를 쉽게 할 수 있는 라이브러리(Python Imaging Library : PIL)
아래 소스에서 에러가 발생이 되면 Pillow모듈 삭제후 다시 설치
>pip uninstall Pillow
>pip install Pillow
-------------------------------------------------------------------------------------------"""
# 배경 이미지 가져오기
img = Image.open("res/앨리스배경.png")
img_array = np.array(img) # 배경 이미지 데이터를 numpy 배열로 변환
type(img_array)
#WordCloud클래스의 객체 생성
wc = WordCloud(
width=1200,
height=800,
scale=2.0,
stopwords=ignore, #금지어
max_font_size=150, #최대 글자 크기
max_words=100, #최대 표시 단어수
mask=img_array, #배경 이미지
background_color="#ffe4ef" #배경색
)
gen = wc.generate(text)
pyplot.figure()
pyplot.imshow(gen, interpolation="bilinear")
pyplot.show()
pyplot.close()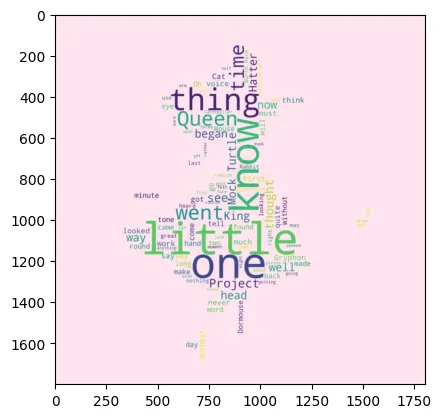
초등학교 분포 나타내기
# 엑셀 파일 내용 기반으로 SVG 이미지 파일에 시도별 초등학교 색상 표시하기
# 엑셀 모듈 설치
# > pip install openpyxl
from pandas import read_excel# 1) 엑셀 파일 읽기
df = read_excel("svg/한국교원대학교_초중등학교위치.xlsx")
df
# 2. 데이터 전처리
## 2-1) 사용할 컬럼만 추출
df.columns
df = df.filter(['학교명', '학교급구분', '소재지도로명주소'])
df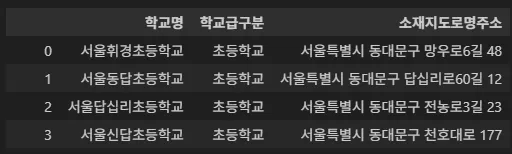
## 2-2 데이터 정제
### 결측치 확인
df.isna().sum()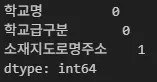
# 결측치 삭제
df = df.dropna()
df.isna().sum()
## 2-3) 주소에서 시 또는 도 이름만 추출해서 컬럼으로 추가
[address.split()[0] for address in df.소재지도로명주소]
df['index'] = df['소재지도로명주소'].str.find(" ")
df
df["시도"] = [a[:i] for a, i in zip(df['소재지도로명주소'], df['index'])]
df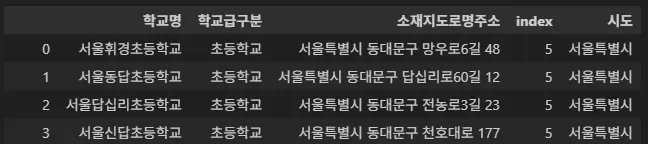
# 3. 데이터 분석
## 1) 지역별, 학교별 집계
df_result = df.filter(['학교명', '학교급구분', '시도'])
df_result
df_result = df_result.groupby(['시도', '학교급구분']).count()
df_result
## 학교명 컬럼을 학교수로 변경
df_result.rename(columns={"학교명":"학교수"}, inplace=True)
df_result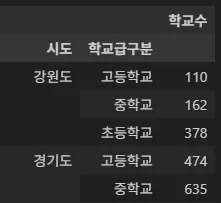
## 2) 시도별로 초등학교만 추출: 딕셔너리
dict_elementry = df_result.loc[[i[1]=='초등학교' for i in df_result.index]]
dict_elementry = dict_elementry.reset_index().set_index("시도")["학교수"].to_dict()
dict_elementry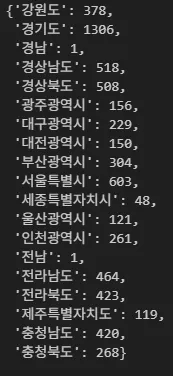
# '경남', '전남' 데이터를 각각 '경상남도', '전라남도' 시에 추가
dict_elementry["경상남도"] += dict_elementry.pop("경남")
dict_elementry["전라남도"] += dict_elementry.pop("전남")
dict_elementry
# 4. 데이터 시각화
"""
PNG와 SVG(Scalable Vector Graphics)의 차이
PNG파일은 Bitmap으로 되어있고, SVG파일은 Vector로 되어있어서 이미지 확대시 차이가 발생한다.
대한민국 SVG 파일 다운받기
https://commons.wikimedia.org
검색 map of South Korea.svg
More Details
Original file 우클릭 다른 이름으로 링크 저장
xml형식이므로 문서로 열어서 fill="" 색상 바꿔보기
"""
# BeautifulSoup(BS4) : HTML과 XML 파일에서 원하는 데이터를 뽑아내는 파이썬 라이브러리
# !pip install beautifulsoup4
from bs4 import BeautifulSoup# 1)svg 파일 읽기
map_svg = None
with open("svg/Korea.svg", 'r', encoding='utf-8') as f:
map_svg = f.read()
map_svg# 2) 색상준비 : https://www.w3schools.com/colors/colors_picker.asp
## 6단계 표현
colors = ["#030303",'#FFB2F5','#F361DC','#D941C5','#990085','#660058']## BeautifulSoup 객체 생성
soup = BeautifulSoup(map_svg, "lxml")
## Korea.svg 이미지에서 <g id='값> <path id='값'> 태그 추출
glist = soup.select('svg > g[id], svg > path[id]')
glist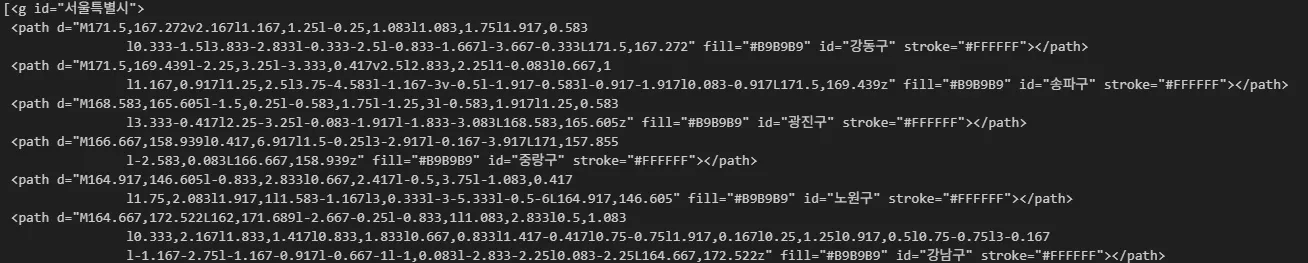
# 지도에 표시할 색상 지정
for item in glist:
if item['id'] not in dict_elementry:
continue
count=dict_elementry[item['id']]
#시도 초등학교수 기준으로 color index 값 설정
if count > 750 : color_index = 5
elif count > 600 : color_index = 4
elif count > 450 : color_index = 3
elif count > 300 : color_index = 2
elif count > 150 : color_index = 1
else : color_index = 0
for p in item.select('g, path'):
p['fill'] = colors[color_index]
#세종특별자치시는 자식태그가 없기 때문에 직접 수정한다.
if item['id'] == '세종특별자치시' :
item['fill'] = colors[color_index]## 3) 지도 시각화 하기
elementry_svg = soup.prettify()
print(elementry_svg)
## 4) 파일 저장
with open('elementary.svg', 'w', encoding='utf-8') as f:
f.write(elementry_svg)
print('elementry_svg 파일 저장!!')## 5) 윈도우에 등록된 연결프로그램 구동
import os # 운영체제와 상호작용하기 위한 모듈
os.system('elementary.svg')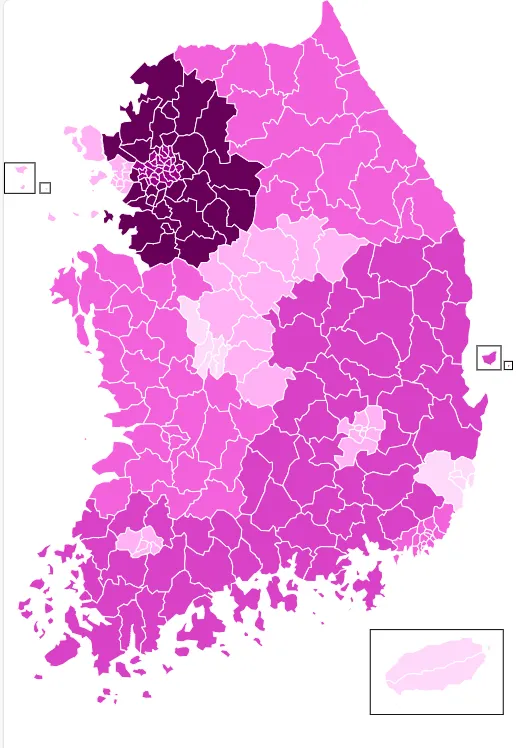
Konlpy
# 참조 https://wikidocs.net/21667
# konlpy : 한글 기반의 자연어 처리 파이선 패키지, 한글 형태소 분석
# ->Hannanum : 카이스트 SWRC에 의해 개발된 자바로 만들어진 형태소 분석기
# ->Kkma : 서울대학교에서 만든 한글 형태소 분석기. 꼬꼬마
# ->Komoran : 자바로 만든 오픈소스 한국어 형태소 분석기
# ->Okt : Open Korean Text (구)트위터 형태소분석기
# ● konlpy 패키지 사용하기 위한 사전 준비 사항
# 1. Microsoft C++ Build Tools 설치
# https://visualstudio.microsoft.com/visual-cpp-build-tools/
# 2. Java (JDK) 설치
# https://www.oracle.com/java/
# 3. JAVA_HOME 환경변수 설정
# 4. KoNLPy 설치
# >pip install konlpy
# 1. 한나눔 형태소 분석기를 이용해 태깅(품사구분)
from konlpy.tag import Hannanum
text = (
"아름답지만 다소 복잡하기도한 한국어는 전세계에서 13번째로 많이 사용되는 언어입니다"
)
print(text)
han = Hannanum()
print(han.analyze(text)) # 각 토큰에 대한 다양한 형태소 후보를 반환합니다
print(han.nouns(text)) # 명사 추출
print(han.morphs(text)) # 형태소 분석 문구 반환
print("-" * 30)
# 2.Kkma : 서울대학교에서 만든 한글 형태소 분석기. 꼬꼬마
from konlpy.tag import Kkma
kkma = Kkma()
print(kkma.morphs(text)) # 형태소 분석 문구 반환
print(kkma.nouns(text)) # 명사 추출
print(kkma.pos(text)) # 품사
print("-" * 30)
# 3. Komoran : 자바로 만든 오픈소스 한국어 형태소 분석기
from konlpy.tag import Komoran
kom = Komoran()
print(kom.morphs(text)) # 형태소 분석 문구 반환
print(kom.nouns(text)) # 명사 추출
print(kom.pos(text)) # 품사
'Courses > 아이티윌 오라클 DBA 과정' 카테고리의 다른 글
| 251016 TIL (0) | 2025.10.16 |
|---|---|
| 251015 TIL (0) | 2025.10.15 |
| 251013 TIL (0) | 2025.10.13 |
| 251010 TIL (0) | 2025.10.10 |
| 251002 TIL (0) | 2025.10.02 |