Data Engineering Fundamentals
2025. 9. 28. 21:47ㆍCERTIFICATES/AWS DEA-C01
데이터의 종류
- 정형 데이터
- 비정형 데이터
- 반정형 데이터
정형 데이터
정의
- 정의된 방식이나 구조로 구성된 데이터
- 관계형 데이터베이스
특징
- 질의가 쉬움
- 행과 열로 구성됨
- 일관된 구조를 가짐
예
- 데이터베이스 테이블
- 일관된 컬럼을 가지는 CSV 파일
- 엑셀 스프레드 시트
비정형 데이터
정의
- 사전에 정의된 구조나 틀이 없는 데이터
특징
- 사전 처리 없이 질의하기 쉽지 않음
- 다양한 형식으로 제공됨
예
- 고정된 형식이 없는 텍스트 파일
- 비디오, 오디오 파일
- 이미지
- 이메일, 워드 처리 문서
반정형 데이터
정의
- 정형 데이터처럼 구조화되지는 않지만 태그, 계층, 기타 패턴의 형태로 어느 정도 구조화된 데이터
- 구조는 있지만 문서 전체에서 일관성을 갖지 않음
특징
- 어떤 방식으로 태그되거나 분류된 요소
- 정형 데이터보다는 유연하지만 비정형 데이터만큼 무질서하지 않음
예
- XML, JSON
- 이메일 헤더
- 다양한 형식의 로그 파일
데이터의 속성
- Volume(크기)
- Velocity(속도)
- Variety(다양성)
Volume(크기)
정의
- 데이터의 양, 크기
특징
- 기가바이트에서 페타바이트 또는 그 이상
- 많은 양의 데이터를 저장, 처리, 분석하는 데 어려움이 있음
예
- 사용자의 게시물, 이미지, 비디오 데이터를 매일 테라바이트씩 처리하는 유명한 소셜 미디어 플랫폼
- 페타바이트 규모의 수년간 거래 데이터를 수집하는 소매업체
Velocity(속도)
정의
- 새 데이터가 생성, 수집, 처리되는 속도
특징
- 빠른 속도는 실시간 또는 거의 실시간 처리 기능을 요구
- 특정 애플리케이션에는 빠른 수집 및 처리가 중요
예
- IoT 기기의 센서 데이터는 매 밀리 초마다 스트리밍
- 밀리 초마다 결정의 차이를 만들어 낼 수 있는 고빈도 거래 시스템
Variety(다양성)
정의
- 다양한 데이터의 유형, 구조, 출처
특징
- 데이터는 정형, 반정형, 비정형일 수 있음
- 데이터는 여러 출처에서 다양한 형식으로 제공될 수 있음
예
- 관계형 데이터베이스(정형), 이메일(비정형), JSON 로그(반정형) 로부터 데이터를 분석하는 기업
- 전자 의료 기록, 웨어러블 헬스 기기, 환자의 피드백 양식에서 데이터를 수집하는 의료 시스템
Data Warehouse VS Data Lake
Data Warehouse
정의
- 분석에 최적화된 중앙 저장소
- 다양한 출처의 데이터를 구조화된 형식으로 저장
특징
- 복잡한 쿼리와 분석을 위해 설계됨
- 데이터는 정제, 변환, 적재됨(ETL)
- 일반적으로 star 또는 snowflake 구조를 사용
- 읽기 작업이 많은 작업에 최적화됨
예
- 아마존 Redshift
- 구글 BigQuery
- 마이크로소프트 Azure SQL Dat Warehouse

- 클릭 스트림, 구매, 카탈로그 데이터 등 모든 데이터가 데이터 웨어하우스에 저장됨
- 회계팀, 분석팀, 머신러닝 등 용도에 맞게 필요한 데이터로 구성된 데이터 마트 생성하여 사용
Data Lake
정의
- 방대한 양의 원시 데이터를 원래 형태 그대로 저장하는 저장소
- 정형, 반정형, 비정형 데이터를 포함
특징
- 사전 정의된 구조 없이 대량의 원시 데이터 저장 가능
- 데이터가 있는 그대로 적재되기 때문에 전처리 필요 없음
- 배치, 실시간, 스트림 처리를 지원
- 데이터 변환 또는 탐색 목적으로 쿼리할 수 있음
예
- 아마존 S3
- Azure Data Lake Storage
- HDFS
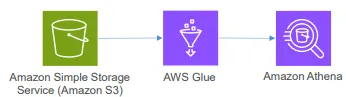
- 모든 정보를 S3에 저장
- Glue를 사용해 비구조적인 데이터에서 구조를 파악
- Athena에서 Glue 데이터 카탈로그를 이용해 데이터 구조를 파악하고 쿼리할 수 있음
비교
| Data Warehouse | Data Lake | |
|---|---|---|
| 스키마 | 데이터를 쓰기 전에 스키마가 정해짐(Schema-on-write) | 데이터를 읽을 때 스키마가 정해짐 (Schema-on-read) |
| 데이터 타입 | 정형 데이터 | 정형 데이터, 비정형 데이터 |
| 민첩성 | 정해진 스키마가 있기 때문에 덜 민첩 | 원시 데이터를 다루기 때문에 더 민첩 |
| 처리 | ETL(추출-변환-적재) | ELT(추출-적재-변환) |
| 비용 | 복잡한 쿼리를 최적화해야 하기 때문에 비쌈 | 비교적 저렴하지만, 많은 양의 데이터를 처리하면서 가격이 오를 수 있음 |
Warehouse와 Lake 선택 기준
Data Warehouse 를 사용해야 할 때
- 정형 데이터를 가지고, 빠르고 복잡한 쿼리가 필요할 때
- 다양한 출처의 데이터 통합이 필수적
- 비즈니스 인텔리전스와 분석
Data Lake 를 사용해야 할 때
- 정형, 반정형, 비정형 데이터 모두 가질 때
- 방대한 양의 데이터를 저장하기 위한 확장성 있고, 비용 효율적인 솔루션 필요
- 데이터의 향후 필요성이 불확실하고, 저장과 처리에 유연성을 갖고 싶을 때
- 고급 분석, 머신러닝, 데이터 발견이 핵심 목표일 때
- 원시 데이터를 데이터 레이크에 수집한 후 처리하여 정제된 데이터를 분석을 위해 데이터 웨어하우스에 옮기는 식으로 두 방식을 조합해서 사용
Data Lakehouse
정의
- 데이터 레이크와 데이터 웨어하우스의 장점을 조합한 하이브리드 데이터 구조
- 데이터 웨어하우스의 성능, 안정성, 기능성을 지키면서
- 데이터 레이크의 유연성, 확장성, 낮은 저장 비용을 유지
특징
- 정형, 비정형 데이터를 모두 지원
- schema-on-write, schema-on-read 모두 가능
- 세부 분석과 머신러닝 작업 모두를 위한 기능 제공
- 일반적으로 클라우드 또는 분산 아키텍처에 구축
- 빅데이터에 ACID 트랜잭션을 적용하는 Delta Lake와 같은 기술의 이점을 가짐
예
- AWS Lake Formation (S3 및 Redshift Spectrum과 함께 사용)
- Delta Lake: Apache Spark와 빅데이터 워크로드에 ACID 트랜잭션을 제공하는 오픈소스 스토리지 계층.
- Databricks Lakehouse Platform: 데이터 레이크와 데이터 웨어하우스의 기능을 결합한 통합 플랫폼.
- Azure Synapse Analytics: 빅데이터와 데이터 웨어하우스를 통합하는 마이크로소프트의 분석 서비스.
Data Mesh

- 2019년에 처음 사용된 용어임, 기술보다는 거버넌스와 조직 방식에 더 가까움
- 개별 팀이 특정 도메인 내의 “데이터 제품(data products)”을 소유함
- 이 데이터 제품들은 조직 내 다양한 “사용 사례(use cases)”를 지원함
- “도메인 기반 데이터 관리(domain-based data management)” 개념임
- 중앙 표준을 기반으로 한 연합형(federated) 거버넌스 방식임
- 셀프 서비스 도구 및 인프라 제공함
- 데이터 레이크, 데이터 웨어하우스 등이 포함될 수 있음
- 하지만 “데이터 메시”는 특정 기술이나 아키텍처가 아니라 “데이터 관리 패러다임”을 의미함
ETL 파이프라인
정의
- Extract, Transform, Load의 약자
- 소스 시스템에서 데이터 웨어하우스로 데이터를 이동시키는 과정
Extract(추출)
- 데이터베이스, CRM, 플랫 파일, API, 기타 데이터 저장소 등 소스 시스템에서 원시 데이터를 가져옴
- 추출 단계에서 데이터 무결성을 보장해야 함
- 요구사항에 따라 실시간 또는 배치 처리로 수행할 수 있음
Transform(변환)
- 추출된 데이터를 대상 데이터 웨어하우스에 적합한 형식으로 변환
- 다양한 작업이 포함될 수 있음
- 데이터 정제(중복 제거, 오류 수정)
- 데이터 보강(다른 소스에서 추가 데이터 결합)
- 형식 변환(날짜 포맷 변경, 문자열 처리)
- 집계 또는 계산(합계, 평균 계산)
- 데이터 인코딩, 디코딩
- 결측값 처리
Load(적재)
- 변환된 데이터를 대상 데이터 웨어하우스 또는 다른 데이터 저장소로 이동
- 배치 방식(한 번에 전체 적재) 또는 스트리밍 방식(데이터가 들어오는 즉시 적재)으로 수행 가능
- 적재 단계에서도 데이터 무결성이 유지되도록 보장해야 함
ETL 파이프라인 관리
- 이 과정은 신뢰할 수 있는 방식으로 자동화해야 함
- AWS Glue
- 자동으로 ETL, ELT 가능
- 오케스트레이션 서비스
- EventBridge
- Amazon Managed Workflows for Apache Airflow(Amazon MWAA)
- AWS Step Functions
- Lambda
- Glue Workflows
Data Source
- JDBC(Java Database Connectivity)
- 플랫폼 독립적
- 언어 종속적(Java)
- ODBC(Open Database Connectivity)
- 플랫폼 종속적(데이터베이스에 액세스하려면 특정 드라이버가 필요)
- 언어 독립적
- 원시 로그
- API
- 스트리밍 데이터
공통 데이터 형식
CSV(Comma-Separated Values)

- 텍스트 기반 형식으로 데이터를 표 형태로 표현
- 각 줄은 하나의 행에 해당, 행 내의 값들은 쉼표로 구분됨
적용 상황
- 소규모 ~ 중간 규모 데이터 셋에 적합
- 서로 다른 기술을 사용하는 시스템 간 데이터 교환에 활용
- 사람이 읽고 편집하기 쉬운 데이터 저장 방식이 필요한 경우
- 데이터베이스나 스프레드시트에서 데이터 가져오기/내보내기 용도
시스템
- SQL 기반 데이터베이스
- 엑셀
- 파이썬 Pandas
- R
- 다양한 ETL 도구
JSON(JavaScript Object Notation)

- 경량, 텍스트 기반의 사람이 읽기 쉬운 데이터 교환 형식
- 키-값 쌍을 기반으로 정형, 반정형 데이터를 표현
적용 상황
- 웹 서버와 웹 클라이언트 간 데이터 교환 시
- 소프트웨어 애플리케이션의 설정 및 구성 관리
- 유연한 스키마나 중첩 구조가 필요한 경우
시스템
- 웹 브라우저
- 다양한 프로그래밍 언어(JavaScript, Python, Java 등)
- RESTful API
- NoSQL 데이터베이스(MongoDB)
Avro
- 데이터를 바이너리 형식으로 저장하면서 스키마까지 함께 포함
- 원본 시스템의 컨텍스트 없이 다른 시스템에서 데이터를 처리할 수 있게 함
적용 상황
- 빅데이터 및 실시간 처리 시스템
- 스키마 진화(데이터 구조 변화)가 필요한 경우
- 시스템 간 데이터 전송을 위한 효율적인 직렬화 방식이 필요할 때
시스템
- Apache Kafka
- Apache Spark
- Apache Flink
- Hadoop Ecosystem
Parquet
- 분석 작업에 최적화된 컬럼 기반 저장 형식
- 효율적인 압축과 인코딩 방식 지원
적용 상황
- 분석 엔진을 사용하여 대규모 데이터 셋을 분석할 때
- 전체 레코드가 아닌 특정 컬럼만 읽는 것이 유리한 경우
- I/O 연산 및 스토리지를 최적화해야 하는 분산 시스템 환경
시스템
- Hadoop 생태계
- Apache Spark
- Apache Hive, Apache Impala
- Amazon Redshift Spectrum
데이터 모델링 개요
- ERD(Entity Relationship Diagram)
- 차원 테이블의 PK는 Fact 테이블의 FK

Data Lineage(데이터 계보)
- 데이터가 소스에서 최종 목적지까지 이동하고 변환되는 과정을 생애주기 전체에 걸쳐 추적하는 시각적 표현
중요성
- 오류를 소스로 추적하는 데 도움을 줌
- 규제 준수를 보장
- 데이터가 시스템 내에서 어떻게 이동, 변환, 소비되는지 명확하게 이해할 수 있게 함
스키마 진화
- 데이터 셋의 스키마를 시간이 지나면서 변경, 적응시켜도 기존 프로세스나 시스템을 방해하지 않고 유지할 수 있는 능력
중요성
- 비즈니스 요구사항 변화에 맞춰 데이터 시스템이 유연하게 적응할 수 있게 함
- 데이터 셋의 컬럼/필드를 추가, 삭제, 수정할 수 있게 함
- 기존 데이터 레코드와의 하위 호환성을 유지
Glue Schema Registry
- 스키마 발견, 호환성 검사, 검증, 등록 등을 지원
데이터베이스 성능 최적화
인덱싱
- 전체 테이블 스캔을 피할 수 있음
- 데이터 고유성과 무결성을 보장
파티션
- 스캔해야 하는 데이터 양을 줄여줌
- 데이터 라이프사이클 관리에 유용
- 병렬 처리를 가능하게 함
압축
- 데이터 전송 속도를 높이고, 스토리지 및 디스크 읽기량을 줄여줌
- GZIP, LZOP, BZIP2, ZSTD(Redshift가 지원하는 압축 포맷)
- 압축률과 속도 간의 다양한 trade-off 존재
- 컬럼 기반 압축(Parquet)
- 한 컬럼 내의 데이터는 같은 데이터 포맷을 갖기 때문에 압축하기 좋음
데이터 샘플링 기법
랜덤 샘플링
- 모든 데이터가 동일한 확률로 선택됨
층화 샘플링
- 모집단을 동질적인 하위 그룹(계층)으로 나눔
- 각 계층 내에서 랜덤 샘플을 추출
- 각 하위 그룹이 균형 있게 대표될 수 있도록 보장
기타
- 체계적 샘플링(일정한 간격 k 마다 샘플 추출)
- 군집 샘플링
- 편의 샘플링
- 판단 샘플
Data Skew 매커니즘
- Data Skew : 분산 컴퓨팅 시스템에서 노드나 파티션 간 데이터가 불균형하게 분포되는 현상
Celebrity 문제
- 트래픽이 불균형하면 균등 파티셔닝을 해도 효과가 없음
- IMDb를 예로 들면, 브래드 피트 관련 트래픽이 한 파티션에 몰려 해당 파티션이 과부화
원인
- 데이터의 비균일 분포
- 부적절한 파티셔닝 전략
- 시간적 skew 발생
- 데이터 분포를 지속 모니터링하고, skew 이슈 발생 시 경고 발생시키는 것이 중요
Data Skew 대응 방법
- 적응형 파티셔닝 : 데이터 특성에 따라 파티셔닝을 동적으로 조정하여 더 균형 잡힌 분포를 보장
- Salting : 데이터 랜덤 요소(salt)를 추가하여 보다 균등하게 분산시킴
- 재파티셔닝 : 현재 분포 특성에 맞춰 데이터를 정기적으로 재분배
- 샘플링 : 데이터 샘플을 사용해 분포를 파악하고 그에 맞춰 처리 전략을 조정
- 사용자 정의 파티셔닝 : 도메인 지식을 기반으로 맞춤 규칙이나 함수를 정의하여 데이터 파티셔닝을 수행
데이터 검증 및 프로파일링
완전성
- 정의 : 필요한 모든 데이터가 존재하며, 필수 요소가 누락되지 않았음을 보장
- 검증 방법 : 결측값 확인, Null 개수, 필드가 채워진 비율
- 중요성 : 누락된 데이터는 잘못된 분석 및 인사이트로 이어질 수 있음
일관성
- 정의 : 데이터 값이 여러 데이터 셋 간에 일관되며 서로 모순되지 않음을 보장
- 검증 방법 : 교차 필드 검증, 서로 다른 소스나 기간의 데이터 비교
- 중요성 : 불일치 데이터는 혼란을 초래하고 잘못된 결론을 낳을 수 있음
정확성
- 정의 : 데이터가 올바르고 신뢰할 수 있으며, 의도한 대상을 정확히 나타냄
- 검증 방법 : 신뢰할 수 있는 소스와 비교, 알려진 규칙/표준에 대한 검증
- 중요성 : 부정확한 데이터는 잘못된 인사이트와 잘못된 의사결정을 초래
무결성
- 정의 : 데이터가 라이프사이클 전체와 여러 시스템에 걸쳐 올바르고 일관성을 유지함
- 검증 방법 : 참조 무결성(DB에서의 외래 키 체크), 데이터 관계 검증
- 중요성 : 데이터 요소 간의 관계가 보존되어야 데이터가 장기간 신뢰 가능
'CERTIFICATES > AWS DEA-C01' 카테고리의 다른 글
| Container (0) | 2025.10.14 |
|---|---|
| Compute (0) | 2025.10.14 |
| Migration and Transfer (0) | 2025.10.14 |
| Database (0) | 2025.10.14 |
| Storage (0) | 2025.09.30 |