Database
2025. 10. 14. 18:10ㆍCERTIFICATES/AWS DEA-C01
Amazon DynamoDB
전통적인 아키텍처
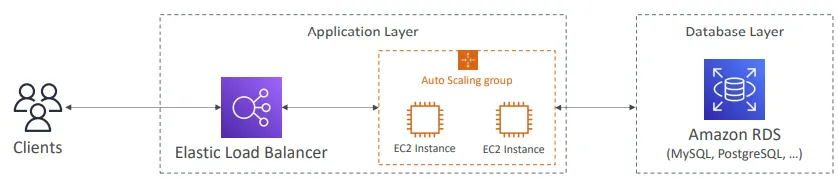
- 전통적인 애플리케이션들은 RDBMS 데이터베이스를 활용
- RDMBS 데이터베이스들은 SQL 쿼리 언어를 지원
- 데이터 모델링 방식에 대한 강력한 제약 조건 존재
- 조인, 집계, 복잡한 연산 수행 가능
- 수직적 향상 : 더 강력한 CPU/RAM/IO 리소스로 업그레이드
- 수평적 확장 : EC2/RDS Read Replica를 추가하여 읽기 성능 확장
NoSQL 데이터베이스
- NOSQL 데이터베이스는 비관계형이며 분산 구조를 가짐
- 대표적인 예: MongoDB, DynamoDB 등
- 조인을 지원하지 않거나 제한적으로만 지원
- 쿼리에 필요한 모든 데이터는 하나의 행에 포함되어 있음
- SUM, AVG 같은 집계 연산을 수행하지 않음
- 수평적 확장에 최적화되어 있음
⇒ NoSQL과 SQL에는 옳고 그름이 있는 것이 아님. 단지 데이터 모델링 방식이 다르고, 사용자 쿼리를 설계하는 관점이 달라질 뿐임
Amazon DynamoDB
- 완전 관리형 서비스, 다중 AZ에 걸친 복제를 통해 고가용성 보장
- NoSQL 데이터베이스로 관계형 데이터베이스가 아님
- 대규모 워크로드에 맞게 확장 가능한 분산 데이터베이스
- 초당 수백만 건 요청, 수조 행, 수백 TB 스토리지까지 지원
- 데이터 조회 시 낮은 지연으로 빠르고 일관된 성능 제공
- IAM과 통합되어 보안, 권한 부여, 관리 기능 제공
- DynamoDB Streams를 통한 이벤트 기반 프로그래밍 지원
- 저비용, 자동 확장 기능 제공
- Table Class : Standard 및 Infrequent Access(IA) 지원
DynamoDB 기본
- DynamoDB는 테이블로 구성됨
- 각 테이블은 Primary Key를 가져야 하며, 생성 시 반드시 정의해야 함
- 각 테이블은 무한 개수의 아이템(=행, Row)을 가질 수 있음
- 각 아이템은 여러 속성을 가지며, 시간이 지나면서 추가 기능하고 null 값도 허용됨
- 아이템의 최대 크기는 400KB임
- 지원 데이터 타입
- 스칼라 타입 : String, Number, Binary, Boolean, Null
- 문서 타입 : List, Map
- 집합 타입 : String Set, Number Set, Binary Set
Primary Keys
옵션 1 : 파티션 키(Hash)
- 각 아이템마다 고유해야 함
- 파티션 키 값이 다양해야 데이터가 고르게 분산됨
- 예: 사용자 테이블에서 User_ID를 파티션 키로 사용

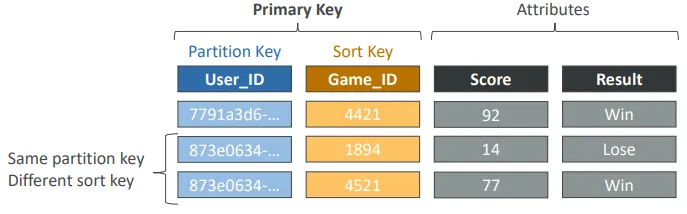
옵션 2 : 파티션 키 + 정렬 키 (Hash + Range)
- 두 키의 조합이 각 아이템마다 고유해야 함
- 데이터는 파티션 키 기준으로 그룹화됨
- 예시 : users-games 테이블
- 파티션 키 : User_ID
- 정렬 키 : Game_ID
빅데이터에서의 DynamoDB
일반 활용 사례
- 모바일 앱(Mobile apps)
- 게임(Gaming)
- 디지털 광고 제공(Digital ad serving)
- 실시간 투표(Live voting)
- 라이브 이벤트에서의 관객 상호작용(Audience interaction)
- 센서 네트워크(Sensor networks)
- 로그 수집(Log ingestion)
- 웹 기반 콘텐츠 접근 제어(Access control)
- Amazon S3 객체의 메타데이터 저장(Metadata storage)
- 이커머스 쇼핑 카트(E-commerce shopping carts)
- 웹 세션 관리(Web session management)
안티 패턴
- 기존 관계형 DB에 강하게 묶여 있는 사전 작성 애플리케이션 → RDS 사용 권장
- 조인 또는 복잡한 트랜잭션 필요 → RDS 사용 권장
- 대용량 바이너리 데이터(BLOB) 저장 → 데이터는 S3, 메타데이터는 DynamoDB
- I/O 비율이 낮은 대용량 데이터 → S3 사용 권장
읽기 / 쓰기 용량 모드
- 테이블의 용량(읽기/쓰기 처리량)을 어떻게 관리할지 제어
- 서로 다른 모드 간 전환은 24시간에 한 번만 가능
- 프로비저닝 모드
- 초당 읽기/쓰기 횟수를 사용자가 직접 지정해야 함
- 사전에 용량 계획이 필요
- 프로비저닝한 읽기/쓰기 용량 단위(RCU/WCU)에 대해 요금 부과됨
- 온디맨드 모드(기본값)
- 워크로드에 따라 읽기/쓰기가 자동으로 확장/축소됨
- 사전 용량 계획 불필요
- 사용한 만큼만 비용 지불, 하지만 상대적으로 더 비쌈
프로비저닝 모드
- 테이블에는 프로비저닝된 읽기/쓰기 용량 단위(RCU/WCU)를 반드시 설정해야 함
- RCU(Read Capacity Units): 읽기 처리량
- WCU(Write Capacity Units): 쓰기 처리량
- 수요에 맞게 처리량을 자동 확장하도록 설정 가능
- 버스트 용량이 모두 소진되면
ProvisionedThroughputExceededException예외 발생 - 이 경우 지수적 백오프 재시도(Exponential Backoff Retry)를 사용하는 것이 권장됨
쓰기 용량 단위(WCU)
- 1WCU = 크기 1KB 이하 아이템에 대해 초당 1건 쓰기를 처리할 수 있는 용량
- 아이템이 1KB를 초과하면, 초과 크기만큼 WCU가 더 소비됨
- 계산 시 아이템 크기는 올림 처리됨
- 예시1: 초당 10개의 아이템을 쓰는데, 아이템 크기가 2KB일 경우
- $10 * \frac{2KB}{1KB} = 20 WCU$
- 예시2: 초당 6개의 아이템을 쓰는데, 아이템 크기가 4.5KB일 경우 → 아이템 크기 올림 5KB
- $6 * \frac{5KB}{1KB} = 30WCU$
- 예시3: 분당 120개의 아이템을 쓰는데, 아이템 크기가 2KB일 경우
- $\frac{120}{60} * \frac{2KB}{1KB} = 4WCU$
Strongly Consistent Read vs Eventually Consistent Read
- Eventually Consistent Read(기본값)
- 쓰기 직후 읽기를 하면, 복제 지연 때문에 오래된 데이터를 받을 수 있음
- 결국 최신 상태와 일치하게 됨
- Strongly Consistent Read(강한 일관성 읽기)
- 쓰기 직후 읽기를 하면, 항상 최신 데이터를 보장
- API 호출 시 ConsistentRead = True 파라미터 설정 필요(GetItem, BatchGetItem, Query, Scan 등에서 사용 가능)
- RCU 2배 소모
읽기 용량 단위(RCU)
- 1RCU = 크기 4KB 이하 아이템에 대해 강한 일관성 읽기는 초당 1회, 느슨한 일관성 읽기는 초당 2회 처리 가능
- 아이템이 4KB를 초과하면, 크기를 4KB 단위로 올림해서 더 많은 RCU를 소비
- 예시1: 초당 10회 강한 일관성 읽기, 아이템 크기 4KB
- $10 * \frac{4KB}{4KB} = 10RCU$
- 예시2 : 초당 16회 느슨한 일관성 읽기, 아이템 크기 12KB
- $\frac{16}{2} * \frac{12KB}{4KB} = 24RCU$
- 예시 3: 초당 10회 강한 일관성 읽기, 아이템 크기 6KB → 6은 4의 배수가 아니므로 8로 올림
- $10 * \frac{8KB}{4KB} = 20RCU$
파티션 내부 동작
- 데이터는 파티션에 저장됨
- 파티션 키는 해싱 알고리즘을 거쳐 어느 파티션에 저장될지 결정됨
- 파티션 수 계산 방법
- $용량 \space 기준 \space 파티션 \space 수 = \frac{RCUsTotal}{3000} + \frac{WCUsTotal}{1000}$
- $크기 \space 기준 \space 파티션 \space 수 = \frac{TotalSize}{10GB}$
- $최종 \space 파티션 \space 수 = ceil(max(용량 \space 기준 \space 파티션 \space 수, 크기 \space 기반 \space 파티션 \space 수))$
- RCU와 WCU는 파티션 전체에 균등하게 분배됨

Throttling
- 프로비저닝된 RCU 또는 WCU를 초과하면
ProvisionedThroughputExceededException오류 발생 - 발생 원인
- Hot Keys: 특정 파티션 키가 과도하게 읽히는 경우(예: 인기 있는 아이템)
- Hot Partitions: 특정 파티션에 요청이 몰리는 경우
- 매우 큰 아이템
- 해결 방법
- 예외 발생 시 지수적 백오프 적용(SDK에 기본 내장)
- 파티션 키를 최대한 균등하게 분산
- RCU 문제가 지속되면 DynamoDB Accelerator(DAX) 사용
온디맨드 모드
- 워크로드에 따라 읽기/쓰기가 자동으로 확장/축소됨
- 용량계획(WCU/RCU) 불필요
- WCU & RCU에 제한 없음, throttling 없음 → 단 비용은 더 비쌈
- 사용한 읽기/쓰기 요청 단위에 따라 요금 부과됨(RRU, WRU 기준)
- 읽기 요청 단위(RRU, Read Request Units) : 읽기 처리량(RCU와 동일 개념)
- 쓰기 요청 단위(WRU, Write Request Units) : 쓰기 처리량(WCU와 동일 개념)
- 프로비저닝 용량 대비 약 2.5배 더 비쌈 → 주의해서 사용해야 함
- 사용 사례 : 워크로드가 불확실한 경우, 애플리케이션 트래픽이 예측 불가능한 경우
데이터 쓰기
PutItem
- 새로운 아이템 생성 또는 동일한 기본 키를 가진 기존 아이템을 완전히 대체
- WCU를 소모
UpdateItem
- 기존 아이템의 속성을 수정하거나, 존재하지 않으면 새 아이템 추가
- 원자적 카운터 구현 가능 → 조건 없이 숫자 속성을 증가시키는 기능
조건부 쓰기
- 특정 조건이 충족될 때만 쓰기/수정/삭제 허용, 그렇지 않으면 에러 반환
- 동시 접근 제어에 도움
- 성능에는 영향 없음
데이터 읽기
GetItem
- 기본 키를 기반으로 읽기 수행
- 기본 키는 HASH 또는 HASH + RANGE 조합일 수 있음
- 일관성 모드
- 기본값: 느슨한 일관성 읽기
- 옵션: 강한 일관성 읽기 → 더 많은 RCU 소모, 지연 가능성 있음
- ProjectionExpression을 사용해 특정 속성만 선택적으로 조회 가능
Query
- Query는 다음 조건을 기반으로 아이템 반환
- KeyConditionExpression
- 파티션 키 값(= 연산자만 사용 가능) → 필수
- 정렬 키 값(=, <, ≤, >, ≥, Between, Begins with) → 선택적
- FilterExpression
- Query 연산 이후, 데이터 반환 전에 추가 필터링 수행
- 비 키 속성에만 사용 가능(Hash 또는 Range 속성에는 불가)
- KeyConditionExpression
- 결과 반환
- 지정된 Limit 개수만큼 아이템 반환
- 또는 최대 1MB 데이터까지 반환
- 결과에 대해 페이지네이션 가능
- 쿼리 가능 대상
- 테이블
- 로컬 보조 인덱스(Local Secondary Index, LSI)
- 글로벌 보조 인덱스(Global Secondary Index, GSI)
Scan
- 테이블 전체를 스캔한 뒤 조건에 맞지 않는 데이터를 필터링 → 비효율적
- 한 번에 최대 1MB 데이터 반환 → 계속 읽으려면 페이지네이션 필요
- 많은 RCU 소모
- Limit을 사용하거나 결과 크기를 줄이고 일시 정지하여 영향을 최소화함
- 성능 향상을 위해 병렬 스캔 사용
- 여러 워커가 동시에 서로 다른 데이터 세그먼트 스캔
- 처리량 증가 → 더 많은 RCU 소모
- 병렬 스캔의 영향을 제한할 때도 일반 Scan과 동일한 방식으로 해야 함
- ProjectionExpression & FilterExpression 사용 가능(RCU 소모량에는 변화 없음)
데이터 삭제
DeleteItem
- 개별 아이템 삭제
- 조건부 삭제 가능
DeleteTable
- 테이블 전체와 그 안의 모든 아이템 삭제
- 모든 아이템에 대해
DeleteItem호출을 반복하는 것보다 훨씬 빠름
배치 연산
- API 호출 수를 줄여 지연을 줄일 수 있음
- 병렬로 작업이 수행되어 효율성이 향상됨
- 일부 요청이 실패할 수 있으며, 실패한 아이템은 재시도 필요
BatchWriteItem
- 한 번의 호출에 최대 25개의
PutItem/DeleteItem실행 가능 - 최대 16MB 데이터, 아이템당 최대 400KB 지원
- 아이템 수정은 불가 →
UpdateItem사용해야 함 - 실패한 쓰기 작업은
UnprocessedItems로 반환 → 지수적 백오프 재시도 또는WCU 증가 필요
BatchGetItem
- 하나 이상의 테이블에서 아이템 반환 가능
- 최대 100개 아이템, 총 데이터는 최대 16MB
- 병렬로 아이템을 가져와 지연을 최소화함
- 실패한 읽기 작업은
UnprocessedKeys로 반환됨 → 지수적 백오프 재시도 또는 RCU 증가 필요
PartiQL
- DynamoDB용 SQL 호환 쿼리 언어
- SQL 문법을 사용해 DynamoDB에서 Select, Insert, Update, Delete 가능
- 여러 DynamoDB 테이블에 걸쳐 쿼리 실행 가능
- PartiQL 쿼리 실행 가능 환경
- AWS Management Console
- NoSQL Workbench for DynamoDB
- DynamoDB API’s
- AWS CLI
- AWS SDK
로컬 보조 인덱스(LSI)
- 테이블에 대해 대체 정렬 키 제공(기본 테이블과 동일한 파티션 키 사용)
- 정렬 키는 하나의 스칼라 속성으로 구성(String, Number, Binary)
- 테이블당 최대 5개 LSI 생성 가능
- 테이블 생성 시에만 정의 가능
- 속성 프로젝션 : 기본 테이블의 일부 또는 전체 속성을 포함할 수 있음(KEYS_ONLY, INCLUDE, ALL)

글로벌 보조 인덱스(GSI)
- 기본 테이블과는 다른 대체 기본 키(HASH 또는 HASH + RANGE)를 가질 수 있음
- 기본 키가 아닌 속성에 대한 쿼리를 빠르게 수행 가능
- 인덱스 키는 스칼라 타입 속성(String, Number, Binary)으로 구성
- 속성 프로젝션 : 기본 테이블 속성 중 일부 또는 전체 포함 가능(KEYS_ONLY, INCLUDE, ALL)
- 인덱스를 위해 RCU와 WCU를 프로비저닝해야함
- 테이블 생성 후에도 추가/수정 가능

인덱스와 Throttling
글로벌 보조 인덱스(GSI)
- GSI에서 쓰기 요청이 throttling되면, 메인 테이블도 함께 throttling됨
- 메인 테이블의 WCU가 충분하더라도 동일하게 영향 받음
- 따라서 GSI 파티션 키를 신중히 선택해야 함
- GSI에 할당할 WCU 용량도 주의 깊게 설정해야 함
로컬 보조 인덱스(LSI)
- 메인 테이블의 WCU와 RCU를 그대로 사용
- 별도의 throttling 고려 사항 없음
PartiQL
- DynamoDB 테이블을 조작하기 위해 SQL 유사 문법 사용
- 일부 SQL 문장을 지원(INSERT, UPDATE, SELECT, DELETE)
- 배치 작업도 지원
DynamoDB Accelerator(DAX)
- DynamoDB용 완전 관리형, 고가용성, 인메모리 캐시 서비스
- 캐싱된 읽기 및 쿼리에 대해 마이크로초 단위 지연시간 제공
- 애플리케이션 로직 수정 불필요(기존 DynamoDB API와 호환)
- Hot Key 문제 해결
- 캐시 TTL 기본값 : 5분
- 클러스터당 최대 10 노드 지원
- 멀티 AZ 지원(운영 환경에서는 최소 3개 노드 권장)
- 보안 지원 : KMS 기반 저장 시 암호화, VPC, IAM, CloudTrail 등과 통합

DAX vs ElastiCache

- DAX
- 개별 객체를 캐싱
- 쿼리/스캔 캐싱
- ⇒ DynamoDB 성능 최적화용
- Amazon ElastiCache
- 집계 결과를 캐싱
- ⇒ 애플리케이션 수준의 고급 캐싱용
DynamoDB Streams
- 테이블에서 발생하는 아이템 단위 변경(생성, 수정,삭제)을 기록한 순서가 보장된 스트림
- 스트림 레코드 활용 방법
- Kinesis Data Streams로 전송
- AWS Lamba로 읽기
- Kinesis Client Library 애플리케이션에서 읽기
- 데이터 보존 기간 : 최대 24시간
- 활용 사례
- 실시간 반응 처리(예: 신규 사용자에게 환영 이메일 발송)
- 분석
- 파생 테이블에 데이터 삽입
- Amazon OpenSearch Service에 데이터 삽입
- 리전 간 복제 구현
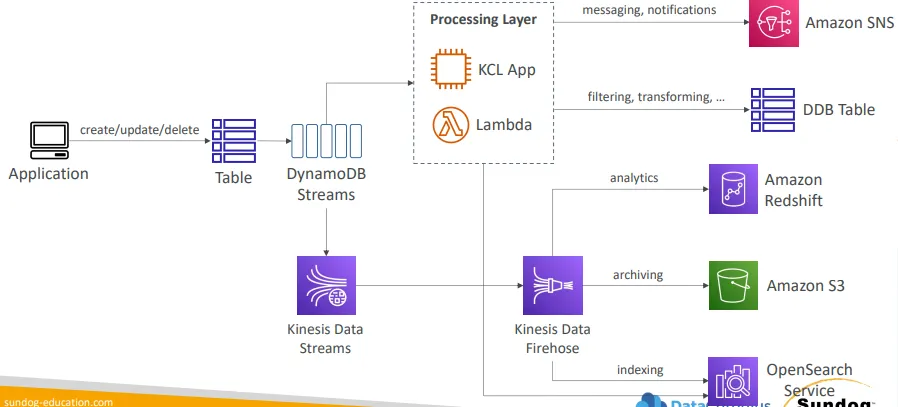
- 스트림에 어떤 정보를 기록할지 선택 가능
- KEYS_ONLY : 변경된 아이템의 키 속성만 기록
- NEW_IMAGE : 변경된 후의 전체 아이템 상태
- OLD_IMAGE : 변경되기 전의 전체 아이템 상태
- NEW_AND_OLD_IMAGES : 변경 전/후의 전체 아이템 상태 모두 기록
- DynamoDB Streams는 Kinesis Data Streams와 마찬가지로 샤드로 구성됨
- 샤드를 프로비저닝할 필요는 없음 → AWS가 자동 관리
- 스트림 활성화 후의 변경 사항만 스트림에 기록(스트림 활성화 전의 기록은 기록하지 않음)
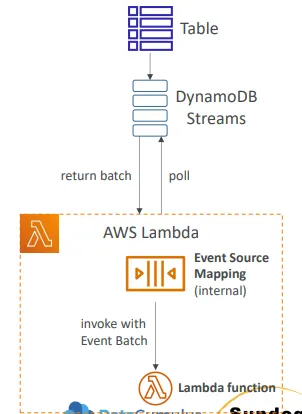
DynamoDB Stream & AWS Lambda
- DynamoDB Streams에서 데이터를 읽으려면 이벤트 소스 매핑을 정의해야 함
- Lambda 함수에 해당 스트림을 읽을 수 있는 적절한 권한이 부여되어야 함
- Lamdba 함수는 동기 방식으로 호출됨
TTL(Time To Live)
- 만료 타임스탬프가 지나면 아이템이 자동으로 삭제됨
- 삭제 시 WCU를 소비하지 않음(추가 비용 X)
- TTL 속성은 Number 타입이어야 하며, 값은 Unix Epoch 타임스탬프 형식이어야 함
- 만료된 아이템은 만료 시점 이후 수일 내에 삭제됨
- 아직 삭제되지 않은 만료된 아이템은 읽기/쿼리/스캔 결과에 포함될 수 있음
- → 이런 항목을 제외하려면 Filter 조건을 사용해야 함
- 만료된 아이템은 LSI와 GSI에서도 모두 삭제됨
- 각 만료된 아이템의 삭제 동작은 DynamoDB Streams에 기록됨
- → 이를 통해 만료된 아이템을 복구할 수도 있음
- 활용 사례
- 규제 요건에 맞게 현재 데이터만 유지하면서 저장 데이터량 줄이기

대용량 객체 패턴
- DynamoDB는 개별 아이템 크기가 최대 400KB로 제한됨
- 큰 파일(이미지, 동영상, 로그 등)을 직접 저장하는 대신, S3에 저장하고 DynamoDB에는 메타데이터만 저장하는 패턴 사용
- 구현 방식
- 대용량 데이터를 Amazon S3에 저장
- S3 객체의 URL 또는 객체 키를 DynamoDB 아이템의 속성으로 저장
- DynamoDB를 통해 메타데이터 조회 및 S3 객체 참조 수행
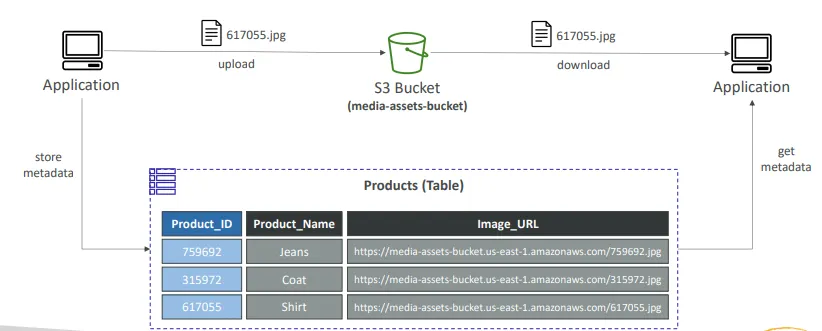
S3 객체 메타데이터 인덱싱

- Application → S3 Bucket
- 사용자가 애플리케이션을 통해 객체를 S3 버킷에 업로드
- S3 Bucket → Labmda Function
- 업로드 이벤트 발생 시 S3 이벤트 트리거로 Lambda 함수가 호출됨
- Lambda Function → DynamoDB Table
- Lambda 함수가 S3 객체의 메타데이터를 추출하여 DynamoDB 테이블에 저장
- Client/Application → DynamoDB Table
- 클라이언트는 애플리케이션을 통해 DynamoDB 테이블에 저장된 메타데이터 조회
- 날짜별 검색
- 고객별 총 저장 용량 계싼
- 특정 속성을 가진 객체 목록 조회
- 특정 기간 동안 업로드 된 객체 찾기
보안 및 기타 기능
보안
- 인터넷을 거치지 않고 DynamoDB에 접근할 수 있도록 VPC Endpoint 제공
- 접근 제한은 IAM으로 완전 제어 가능
- 저장 데이터는 AWS KMS로 암호화
- 전송 중 데이터는 SSL/TLS로 암호화
백업 및 복구
- RDS와 같이 시점 복구(PITR, Point-in-time Recovery) 지원
- 성능에 영향 없음
글로벌 테이블
- 다중 리전
- 다중 활성
- 완전 복제
- 고성능
DynamoDB Local
- 인터넷 없이 로컬 환경에서 DynamoDB 애플리케이션 개발 및 테스트 가능
- 실제 AWS 리소스 사용하지 않음
데이터 마이그레이션
- AWS Database Migration Service(DMS)를 사용해 MongoDB, Oracle, MySQL, S3 등에서 DynamoDB로 마이그레이션 가능
사용자가 DynamoDB에 직접 접근

세분화된 접근 제어
- Web Identity Fedration 또는 Amazon Cognito Identity Pools를 사용하면, 각 사용자가 고유한 AWS 자격 증명을 부여받을 수 있음
- 이러한 사용자에게 IAM Role을 할당하고, Condition을 설정하여 DynamoDB API 접근을 세밀하게 제한 가능
- Leading Keys : 사용자가 접근할 수 있는 Primary Key 범위를 제한하여 행 단위 접근 제어 구현
- Attributes : 사용자가 볼 수 있는 특정 속성만 허용하여 열 단위 접근 제어 구현
Amazon RDS
RDS란?
- 호스팅된 관계형 데이터베이스
- 지원 엔진 : Amazon Aurora, MySQL, PostgreSQL, MariaDB, Oracle, SQL Server
- 빅데이터용 서비스 아님
- 시험에서는 사용하지 말아야 할 예시로 등장할 수 있음
- RDS에서 Redshift 등으로 마이그레이션하는 맥락에서 등장할 수 있음
ACID
- RDS 데이터베이스는 완전한 ACID 특성을 지원
- Atomicity(원자성) : 트랜잭션은 전부 수행되거나 전혀 수행되지 않음
- Consistency(일관성) : 트랜잭션 수행 전후로 데이터의 제약 조건이 항상 유지됨
- Isolation(격리성) : 동시에 실행되는 트랜잭션들이 서로 영향을 미치지 않음
- Durability(지속성) : 트랜잭션이 커밋되면 시스템 장애가 발생하더라도 결과가 보존됨
Amazon Aurora
- MySQL 및 PostgreSQL과 호환
- MySQL보다 최대 5배, PostgreSQL보다 최대 3배 빠름
- 상용 데이터베이스 대비 비용이 1/10 수준
- 데이터베이스 볼륨당 최대 128TB까지 확장 가능
- 최대 15개의 읽기 복제본 지원
- S3로 지속적인 백업 수행
- 리전 간 및 가용 영역 간 복제 지원
- Aurora Serverless를 통해 자동으로 스케일링함
Aurora 보안
- VPC 네트워크 격리 제원
- KMS를 사용한 저장 데이터 암호화 지원
- 데이터, 백업, 스냅샷, 복제본 모두 암호화 가능
- SSL을 통한 전송 중 암호화 지원
LOCK 명령어 사용
- 관계형 데이터베이스는 동시에 두 개의 트랜잭션이 동일한 데이터에 쓰기 작업을 하거나, 쓰기 중에 다른 트랜잭션이 읽는 것을 방지하기 위해 암묵적으로 테이블에 Lock을 설정
- 데이터 무결성과 동시성 제어를 보장하기 위해 테이블이나 행을 명시적으로 잠글 수 있음
- Lock의 종류
- Shared Lock(공유 락) : 읽기는 허용하지만 쓰기는 금지. 여러 트랜잭션이 동시에 공유 락을 가질 수 있음(For Share)
- Exclusive Lock(배타 락) : 해당 리소스에 대해 읽기와 쓰기 모두 차단. 단 하나의 트랜잭션만 배타 락을 가질 수 있음(For Update)
예시(MySQL)
- 테이블 전체 잠금
Lock Tables employees WRITE;- employees 테이블 전체를 쓰기 작업을 위해 잠금
- 잠금을 해제하려면
UNLOCK TABLES명령어 사용 - Redshift도 동일한 목적의
LOCK명령어 지원
- 공유 락 : 읽기는 허용하지만 트랜잭션 동안 다른 쓰기를 방지
select * from employees where department = 'Finance' for share;
- 배타 락 : 트랜잭션 동안 모든 읽기와 쓰기 차단
select * from employees where emplyee_id = 123 for update;
- 모든 트랜잭션의 Lock이 정상적으로 완료돼야 하며, 그렇지 않으면 교착 상태 발생
Amazon RDS 운영 가이드라인
- CloudWatch를 사용해 메모리, CPU, 스토리지, 복제 지연 등을 모니터링
- 일일 쓰기 IOPS가 낮은 시간대에 자동 백업이 수행되도록 설정
- I/O 성능이 부족하면 장애 발생 시 복구 속도가 느려짐
- 더 높은 I/O 성능을 가진 DB 인스턴스로 마이그레이션
- General Purpose 또는 Porvisioned IOPS 스토리지로 이전
- DNS의 TTL 값을 앱에서 30초 이하로 설정
- 장애 조치를 사전에 테스트
- 작업 집합 전체를 포함할 수 있을 만큼 충분한 RAM을 프로비저닝
- 읽기 IOPS 지표가 작고 안정적이라면 시스템 상태가 양호
- Amazon API Gateway의 Rate Limit 기능을 이용해 데이터베이스 보호 가능
RDS에서의 쿼리 최적화
- SELECT 문 성능 향상을 위해 인덱스 사용
- 실행 계획을 통해 필요한 인덱스 식별
- 전체 테이블 스캔은 피해야 함
ANALYZE TABLE명령을 주기적으로 실행하여 통계 정보 갱신- WHERE 절을 단순화하여 불필요한 조건 제거
- 엔진 별로 특화된 최적화
DB별 튜닝 팁
MySQL/MariaDB
- 테이블 크기는 16TB 이하, 이상적으로는 100GB 이하로 유지
- 활성 테이블의 인덱스 전체를 메모리에 적재할 수 있을 만큼 충분한 RAM 확보
- 테이블 개수는 10,000개 미만으로 유지하는 것이 바람직함
- 스토리지 엔진으로 InnoDB 사용
PostgreSQL
- 대량 데이터 로딩 시에는
- DB 백업 및 Multi-AZ 복제 기능 비활성화
maintenance_work_mem,max_wal_size,checkpoint_timeout파라미터 조정synchronous_commitautovacuum비활성화- 테이블 로그 활성화
- 로딩 후에는 autovacuum을 반드시 활성화하여 테이블 청소 및 통계 갱신 유지
SQL Server
- RDS DB 이벤트를 사용하여 장애 조치를 모니터링
- SImple Recovery Mode, Offline Mode, Read-Only Mode를 활성화하지 말 것
→ Multi-AZ 구성을 깨뜨림 - 모든 가용 영역에 배포하여 고가용성 확보
Oracle
- 알아서 잘함…
DocumentDB
- Aurora가 PostgreSQL/MySQL의 AWS 구현체인 것처럼, DocumentDB는 MongoDB(NoSQL 데이터베이스)의 AWS 구현체임
- MongoDB는 JSON 데이터를 저장, 조회, 인덱싱하기 위해 사용됨
- Aurora와 유사한 배포 개념을 가짐
- 완전 관리형 서비스이며, 3개 가용 영역에 걸친 복제를 통해 고가용성 보장
- 스토리지가 자동으로 10GB 단위로 확장됨
- 초당 수백만 건의 요청을 처리할 수 있도록 자동으로 스케일링함
Amazon MemoryDB for Redis
- Redis와 호환되는 인메모리 데이터베이스 서비스
- 초당 1억 6천만 건 이상의 요청을 처리할 수 있는 초고속 성능 제공
- Multi-AZ 트랜잭션 로그를 사용한 내구성 있는 인메모리 데이터 저장소 제공
- 수십 GB에서 수백 TB까지 스토리지를 매끄럽게 확장 가능
- 주요 사용 사례 : 웹 및 모바일 애플리케이션, 온라인 게임, 미디어 스트리밍 등

Amazon Keyspaces(for Apache Cassandra)
- Apache Cassandra는 오픈소스 NoSQL 분산 데이터베이스
- Apache Cassandra와 호환되는 완전 관리형 데이터베이스 서비스
- 서버리스 구조로 확장성, 고가용성, 완전 관리형 서비스 제공
- 애플리케이션 트래픽에 따라 테이블 용량을 자동으로 확장/축소
- 테이블은 여러 가용 영역에 걸쳐 3중 복제됨
- Cassandra Query Language(CQL)을 사용하여 쿼리 수행
- 어떤 규모에서도 한 자릿수 밀리초 수준의 지연 시간을 유지하며, 초당 수천 건의 요청 처리 가능
- 용량 모드 : On-demand 모드, 오토스케일링 기능이 있는 Provisioned 모드 중 선택 가능
- 암호화, 백업, 시점 복구(PITR) 기능 지원 - 최대 35일까지 복구 가능
- 주요 사용 사례 : IOT 기기 정보 저장, 시계열 데이터 저장 등
Apache Neptune
- 완전 관리형 그래프 데이터베이스
- 대표적인 그래프 데이터셋 예시는 소셜 네트워크
- 사용자는 친구 관계를 가짐
- 게시글을 댓글을 가짐
- 댓글은 사용자로부터 좋아요를 받음
- 사용자는 게시글을 공유하고 좋아요를 누름 등
- 3개의 가용 영역에 걸쳐 고가용성을 제공하며, 최대 15개의 읽기 복제본 지원
- 고도로 연결된 데이터셋을 다루는 애플리케이션을 구축 및 실행 가능
- 이러한 복잡하고 비용이 큰 쿼리를 처리하도록 최적화되어 있음
- 수십억 개의 관계를 저장하고 밀리초 단위의 지연 시간으로 그래프 쿼리 수행 가능
- 여러 AZ에 걸친 복제를 통해 높은 내결함성과 가용성 보장
- 주요 사용 사례
- 지식 그래프(위키피디아)
- 사기 탐지
- 추천 엔진
- 소셜 네트워킹
Apache Neptune 쿼리 언어
- Gremlin
- openCypher
- SPARQL

Amazon Timestream
- 완전 관리형, 고속, 확장 가능, 서버리스 시계열 데이터베이스
- 오토스케일링되어 워크로드에 맞게 용량 조정
- 하루에 수조 건의 이벤트를 저장 및 분석 가능
- 관계형 데이터베이스보다 최대 수천 배 빠르고, 비용은 1/10 수준
- 예약 쿼리, 다중 측정 레코드, SQL 호환성 지원
- 데이터 저장 계층화 구조를 가짐
- 최근 데이터는 메모리에 저장
- 이전 데이터는 비용 효율적인 스토리지에 저장
- 내장된 시계열 분석 함수 제공 - 실시간에 가까운 데이터 패턴 분석 가능
- 전송 중 암호화 및 저장 중 암호화 지원
- 주요 사용 사례
- IoT 애플리케이션
- 운영 모니터링
- 실시간 분석

Amazon Redshift
Redshift란
- 완전관리형 페타바이트 규모의 데이터 웨어하우스 서비스
- 다른 데이터 웨어하우스보다 최대 10배 빠른 성능 제공
- 머신러닝 , 대규모 병렬 쿼리 실행, 컬럼형 스토리지
- OLTP 용이 아니라 OLAP 용으로 설계됨
- 비용 효율적임
- SQL, ODBC, JDBC 인터페이스를 통해 접근 가능
- 수요에 따라 스케일 업/다운 가능
- 내장된 복제 및 백업 기능 제공
- CloudWatch / CloudTrail을 통한 모니터링 지원
Redshift 사용 사례
- 분석 워크로드 가속화
- 데이터 웨어하우스와 데이터 레이크 통합
- 데이터 웨어하우스 현대화
- 전 세계 매출 데이터 분석
- 과거 주식 거래 데이터 저장
- 광고 노출 및 클릭 데이터 분석
- 게임 데이터 집계
- 소셜 트렌드 분석
Redshift 아키텍처
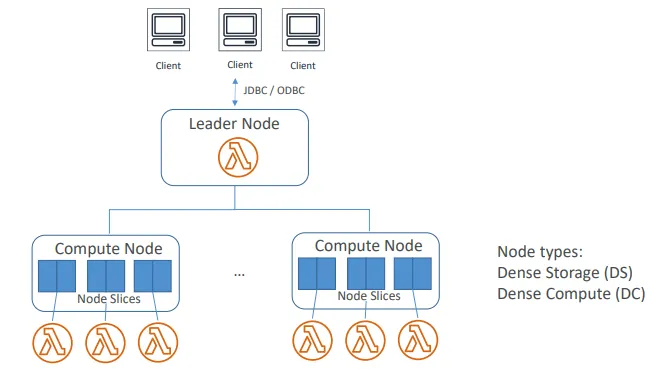
- 클러스터 : Redshift의 가장 상위 레벨의 인프라 구성 요소
- 하나의 클러스터는 리더 노드와 하나 이상의 컴퓨트 노드로 구성
- 노드 수는 최소 1개에서 최대 128개까지 구성 가능(노드 타입에 따라 다름)
- 무한히 확장되는 구조는 아니지만 128개의 노드로 매우 대용량 데이터 저장 가능
- 각 클러스터에는 하나 이상의 데이터베이스 포함 가능
- 사용자 데이터는 컴퓨트 노드에 저장됨
- 리더 노드는 클라이언트 프로그램과 컴퓨트 노드 간의 통신 관리
⇒ 외부 클라이언트와 내부 노드 간의 인터페이스 역할- 클라이언트 애플리케이션으로부터 쿼리를 수신하고 쿼리를 파싱하여 실행 계획 생성
- 실행 계획은 쿼리를 처리하기 위한 순서화된 단계의 집합
- 리더 노드는 컴퓨트 노드들과 병렬 실행을 조정
- 중간 결과를 수집 및 집계
- 최종 결과를 클라이언트 애플리케이션에 반환
- 컴퓨트 노드
- 리더 노드로부터 받은 실행 게획의 각 단계를 실제로 수행
- 노드 간 데이터 전송을 수행하며, 쿼리 결과를 리더 노드로 전달
- 각 컴퓨트 노드는 전용 CPU, 메모리, 디스크 스토리지를 가짐
- 노드 슬라이스
- 각 컴퓨트 노드는 여러 개의 슬라이스로 분할됨
- 각 슬라이스는 노드의 일부 메모리 및 디스크 공간을 할당받음
- 슬라이스는 해당 노드에 할당된 워크로드의 일부를 병렬로 처리
- 슬라이스 개수는 클러스터 노드 크기에 따라 결정됨
Redshift Spectrum
- S3에 저장된 비정형 데이터를 로드하지 않고 직접 쿼리 가능
- 동시성 제약 없음
- 수평 확장 가능
- 스토리지와 컴퓨팅 리소스가 분리되어 있음
- 다양한 데이터 형식 지원
- Gzip, Snappy 압축 지원
Redshift 성능
- MPP(Massively Parallel Processing) 구조 사용
- 컬럼 기반 저장
- 컬럼 압축
Redshift 내구성
- 클러스터 내부 복제 수행
- S3 백업
- 비동기 복제를 통해 다른 리전으로 데이터 복제
- 자동 스냅샷
- 장애가 발생한 드라이브나 노드는 자동으로 교체
- 단, 단일 가용 영역에만 한정
- RA3 클러스터에 대해 Multi-AZ 지원
Redshift 확장
- 필요에 따른 수직 확장과 수평 확장 가능
- 스케일링 과정
- 새로운 클러스터가 생성되는 동안 기존 클러스터는 읽기 전용 상태로 유지
- CNAME이 새 클러스터로 전환(몇 분간의 다운타임 발생)
- 데이터는 병렬 방식으로 새로운 컴퓨트 노드로 이동
Redshift 분산 스타일
- AUTO : Redshift가 데이터 크기를 기반으로 자동으로 결정
- EVEN : 행을 라운드로빈 방식으로 슬라이스 전반에 분산

- KEY : 행을 하나의 컬럼 기준으로 분산
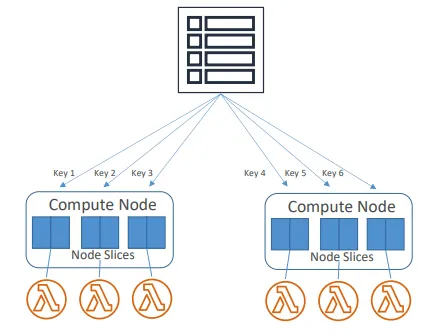
- ALL : 전체 테이블을 모든 노드에 복제
데이터 가져오기/내보내기
- COPY 명령어
- 병렬 처리되어 효율적
- S3, EMR, DynamoDB, 원격 호스트로부터 데이터 로드 가능
- S3의 경우 Manifest file과 IAM 역할 필요
- UNLOAD 명령어
- 테이블의 데이터를 S3 파일로 언로드
- 향상된 VPC 라우팅
- S3 자동 복사 지원
- Amazon Aurora Zero-ETL 통합 지원
- Aurora → Redshift 자동 복제 수행
- Redshift 스트리밍 수집
- Kinesis Data Streams 또는 Amazon MSK로부터 데이터 수집 가능
COPY 명령어
- COPY를 사용하여 Redshift 외부에서 대량의 데이터를 로드
- 데이터가 이미 Redshift의 다른 테이블에 있는 경우
- INSERT INTO … SELECT 사용
- 또는 CREATE TABLE AS 사용
- COPY는 S3에서 데이터를 로드할 때 복호화 가능
- 하드웨어 가속 SSL을 사용하여 속도 유지
- Gzip, lzop, Bzip2 압축 지원으로 추가적인 속도 향상 가능
- 자동 압축 옵션 제공
- 로드 중인 데이터를 분석하여 최적의 압축 구조를 결정
- 특수 사례 : 폭이 좁은 테이블(행이 많고 컬럼이 적은 경우)
- 가능하다면 하나의 COPY 트랜잭션으로 로드
- 그렇지 않으면 숨겨진 메타데이터 컬럼이 너무 많은 공간 차지
Redshift 교차 리전 스냅샷 복사를 위한 copy grant
- KMS로 암호화된 Redshift 클러스터와 그 스냅샷이 있는 경우
- 해당 스냅샷을 다른 리전으로 백업용 복사하고 싶음
- 대상 리전에서
- KMS 키가 없다면 새로운 KMS키 생성
- 스냅샷 복사 권한에 대해 고유한 이름을 지정
- 생성한 Copy Grant와 연결할 KMS 키 ID 지정
- 소스 리전에서
- 방금 생성한 Copy Grant로의 스냅샷 복사 기능을 활성화
DBLINK
- Redshift를 PostgreSQL과 연결
- PostgreSQL과 Redshift 간 데이터를 복사하고 동기화하기에 좋은 방법
CREATE EXTENSION postgres_fdw;
CREATE EXTENSION dblink;
CREATE SERVER foreign_server
FOREIGN DATA WRAPPER postgres_fdw
OPTIONS (host '<amazon_redshift _ip>', port '<port>', dbname '<database_name>', sslmode
'require');
CREATE USER MAPPING FOR <rds_postgresql_username>
SERVER foreign_server
OPTIONS (user '<amazon_redshift_username>', password '<password>');다른 서비스와의 통합
- S3
- DynamoDB
- EMR/EC2
- Data Pipeline
- Database Migration Service(DMS)
Redshift 워크로드 관리(WLM)
- 짧고 빠른 쿼리와 길고 느린 쿼리의 우선순위 조정
- 쿼리 큐 사용
- 콘솔, CLI, API를 통해 구성 가능
동시성 확장
- 동시 읽기 쿼리 증가 시 자동으로 클러스터 용량 추가
- 사실상 무제한의 동시 사용자 및 쿼리 지원
- WLM 큐가 어떤 쿼리를 동시성 확장 클러스터로 보낼지 관리함
자동 워크로드 관리
- 최대 8개의 큐 생성
- 기본값으로 5개의 큐가 생성되며, 메모리가 균등하게 할당됨
- 대규모 쿼리(대형 해시 조인 등)의 경우 동시성이 낮아짐
- 소규모 쿼리(INSERT, 스캔, 집계 등)의 경우 동시성이 높아짐
- 쿼리 큐 구성 요소
- Priority(우선순위)
- Concurrency scailing mode(동시성 ㅗ학장 모드)
- User groups(사용자 그룹)
- Query groups(쿼리 그룹)
- Query monitoring rule(쿼리 모니터링 규칙)
수동 워크로드 관리
- 기본 큐는 동시성 수준 5(한 번에 5개 쿼리 실행)로 설정됨
- 슈퍼유저 큐는 동시성 수준 1로 설정됨
- 최대 8개의 큐를 정의할 수 있으며, 각 큐는 최대 동시성 수준 50까지 설정 가능
- 각 큐는 다음 항목들을 개별적으로 정의 가능
- 동시성 확장 모드
- 동시성 수준
- 사용자 그룹
- 쿼리 그룹
- 메모리
- 타임아웃
- 쿼리 모니터링 규칙
- 쿼리 큐 홉핑 기능도 활성화 가능
- 타임아웃된 쿼리는 다음 큐로 이동(hop)하여 다시 시도
Short Query Acceleration(SQA)
- 짧게 실행되는 쿼리를 긴 쿼리보다 우선 처리
- 짧은 쿼리는 전용 공간에서 실행되며, 긴 쿼리 뒤에서 큐 대기하지 않음
- 짧은 쿼리용 WLM 큐 대신 SQA를 사용 가능
- SQA가 작동하는 쿼리 유형
- CREATE TABLE AS(CTAS)
- 읽기 전용 쿼리(SELECT 문)
- 머신러닝을 사용하여 쿼리 실행 시간 예측
- 짧은 쿼리로 간주할 시간 기준을 사용자가 직접 설정 가능
Redshift 클러스터 크기 조정
- Elastic Resize
- 동일한 노드 타입의 노드를 빠르게 추가 또는 제거
- 노드 타입 변경도 가능하지만, 연결이 끊어지며 새로운 클러스터가 생성됨
- 클러스터는 몇 분간 다운됨, 이 때 가능한 한 연결을 유지하려 시도
- 일부 dc2 및 ra3 노드 타입은 용량을 2배로 늘리거나 절반으로 줄이는 것만 가능
- Classic Resize
- 노드 타입 또는 노드 개수 변경 수행
- 클러스터는 수 시간에서 수일 동안 읽기 전용 상태가 됨
- 스냅샷, 복원, 리사이즈
- 클래식 리사이즈 중에도 클러스터 가용성을 유지하기 위해 사용
- 클러스터를 복사한 후 새 클러스터를 리사이즈
VACUUM 명령어
- 삭제된 행으로부터 공간을 회수하고 정렬 순서를 복원
- VACUUM FULL : 전체 정리 수행
- VACUUM DELETE ONLY : 정렬을 건너뜀
- VACUUM SORT ONLY : 공간을 회수하지 않음
- VACUUM REINDEX : 정렬 키 컬럼의 분포를 다시 분석한 후 전체 VACUUM 수행
최신 Redshift 기능
- RA3노드(Managed Storage 포함)
- 컴퓨트와 스토리지를 독립적으로 확장 가능
- SSD 기반 스토리지 사용
- Redshift 데이터 레이크 내보내기
- Redshift 쿼리 결과를 Apache Parquet 형식으로 S3에 언로드
- Parquet은 언로드 속도가 2배 빠르고, 스토리지 사용량이 최대 6배 적음
- Redshift Spectrum, Athena, EMR, SageMaker와 호환됨
- 자동 파티셔닝 지원
- 공간 데이터 타입
- GEOMETRY, GEOGRAPHY 지원
- 리전 간 데이터 공유
- 데이터 복사 없이 Redshift 클러스터 간에 실시간 데이터 공유 가능
- RA3 노드 타입 필요
- 리전 간 및 계정 간에서도 보안 제공
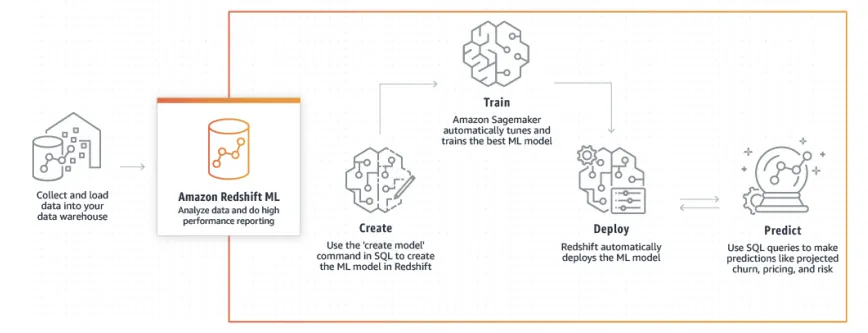
Amazon Redshift ML
Redshift 안티 패턴
- 작은 데이터셋 → RDS 사용 권장
- OLTP 워크로드 → RDS 또는 DynamoDB 사용 권장
- 비정형 데이터 → EML 등으로 먼저 ETL 수행 후 사용
- 대용량 바이너리 데이터(BLOB) → 파일 자체를 저장하지 말고, S3에 저장된 파일의 참조만 저장
Redshift 보안 관련 사항
- 하드웨어 보안 모듈(HSM) 사용
- Redshift 와 HSM 간에 신뢰할 수 있는 연결을 구성하기 위해 클라이언트 및 서버 인증서를 사용해야 함
- 암호화되지 않은 클러스터를 HSM 암호화 클러스터로 마이그레이션하려면, 새로운 암호화 클러스터를 생성한 후 데이터를 이동해야 함
- 사용자 또는 그룹에 대한 접근 권한 정의
- SQL의 GRANT 또는 REVOKE 명령어 사용
- 예:
GRANT SELECT on TABLE foo TO bob;
Redshift Serverless
- 워크로드에 대해 자동 확장 및 자동 프로비저닝 수행
- 비용 및 성능 최적화
- 사용한 만큼만 요금 지불
- 머신러닝을 사용하여 가변적이고 비정기적인 워크로드에서도 성능 유지
- 개발 및 테스트 환경을 손쉽게 신속히 생성 가능
- 즉석 비즈니스 분석에 용이
- 사용자는 서버리스 엔드포인트, JDBC/ODBC 연결 또는 콘솔의 쿼리 에디터를 통해 직접 쿼리 가능
Redshift Serverless 시작하기
- 다음 IAM 정책이 포함된 IAM Role이 필요

- 다음 항목들을 정의
- 데이터베이스 이름
- 관리자 자격 증명
- VPC 설정
- 암호화 설정 - 기본적으로 AWS 소유 KMS
- 감사 로깅 설정
- 생성 후에는 스냅샷 및 복구 지점 관리 가능
Redshift Serverless의 리소스 스케일링
- 용량은 Redshift Processing Units(RPU) 단위로 측정됨
- RPU-시간 단위(초 단위)와 스토리지 비용을 함께 지불
- 기준 RPU
- 기본 용량 조정 가능
- 기본값은 AUTO로 설정됨
- 32 ~ 512 RPU 범위 내에서 조정 가능하며 이를 통해 쿼리 성능 향상 가능
- 최대 RPU
- 비용 제어를 위해 사용 한도 설정 가능
- 또는 처리량 향상을 위해 향상시킬 수 있음
Redshift Serverless
- 일반 Redshift와 동일한 기능을 수행하지만, 다음은 지원하지 않음
- 파라미터 그룹
- 워크로드 관리
- AWS 파트너 통합
- 유지 관리 윈도우/버전 트랙
- 공개 엔드포인트 - 아직 지원 X
- VPC 내부에서만 접근 가능
Redshift Serverless 모니터링
- 모니터링 뷰
SYS_QUERY_HISTORYSYS_LOAD_HISTORYSYS_SERVERLESS_USAGE- 그 외 다수의 시스템 뷰
- CloudWatch 로그
- 연결 및 사용자 로그는 기본적으로 활성화됨
- 사용자 활동 로그는 선택적으로 활성화 가능
- 로그 경로 : /aws/redshift/serverless/
- CloudWatch 메트릭
- 주요 지표 :
QueriesCompletedPerSecond,QueryDuration,QueriesRunning등 - 차원 : DatabaseName, latency(Short, medium/long), QueryType, stage
- 주요 지표 :
Redshift Materialized View
- 하나 이상의 기본 테이블에 대한 SQL 쿼리 결과를 미리 계산해 저장
- 일반 뷰와 달리 쿼리 결과 자체를 실제로 저장
- 복잡한 쿼리를 데이터 웨어하우스, 특히 대용량 테이블에서 실행할 때 성능을 크게 향상시킴
- 일반 테이블이나 뷰처럼 쿼리 가능
- 쿼리는 기본 테이블을 다시 조회하지 않고, 미리 계산된 결과를 사용하므로 훨씬 빠르게 실행됨
- 예측 가능하고 반복적인 쿼리(Amazon QuickSight 대시보드용 데이터)에 특히 유용
Materialized View 사용
CREATE MATERIALIZED VIEW ...명령어로 생성
CREATE MATERIALIZED VIEW tickets_mv AS
select catgroup,
sum(qtysold) as sold
from category c, event e, sales s
where c.catid = e.catid
and e.eventid = s.eventid
group by catgroup;- 갱신 유지 방법
REFRESH MATERIALIZED VIEW ...명령어 상요- 생성 시
AUTO REFRESH옵션 설정 가능
- 일반 테이블이나 뷰처럼 쿼리 가능
- 다른 Materialized View 로부터 새로운 Materialized View 생성 가능
- 비용이 큰 조인을 재사용할 때 유용
Redshift 데이터 공유
- 읽기 전용으로 Redshift 클러스터 간 실시간 데이터를 안전하게 공유
- 필요성
- 워크로드 격리
- 그룹 간 협업
- 개발/테스트/운영 환경 간 데이터 공유
- AWS Data Exchange에서 라이선스 기반 데이터 접근 제공
- 공유 가능한 객체 : 데이터베이스, 스키마, 테이블, 뷰, 사용자 정의 함수
- 세밀한 접근 제어 지원
- 프로듀서 / 컨슈머 구조 사용
- 프로듀서가 보안 제어
- 격리를 통해 프로듀서의 성능이 컨슈머에 의해 영향을 받지 않도록 보장
- 데이터는 실시간이며 트랜잭션 일관성을 유지
- 양쪽 클러스터 모두 암호화되어야 하며, RA3 노드 타입을 사용해야 함
- 리전 간 데이터 공유 시 전송 요금이 발생함
- 데이터 공유 유형
- Standard
- AWS Data Exchage 기반 공유
- AWS Lake Formation 관리형 공유
Redshift Lambda UDF
- SQL 쿼리 내부에서 AWS Lambda의 사용자 정의 함수 사용 가능
SELECT a, b FROM t1 WHERE lambda_multiply(a,b) = 64- 원하는 언어로 작성 가능
- 원하는 작업 수행 가능
- 다른 AWS 서비스 호출(AI)
- 외부 시스템 접근
- 위치 서비스와 통합 가능
CREATE EXTERNAL FUNCTION명령어로 등록CREATE EXTERNAL FUNCTION exfunc_sum(INT,INT) RETURNS INT VOLATILE LAMBDA 'lambda_sum' IAM_ROLE 'arn:aws:iam::123456789012:role/Redshift-Exfunc-Test';
- 권한 부여시
GRANT USAGE ON LANGUAGE EXFUNC명령어를 사용해야 함 - 클러스터의 IAM Role에 Lambda 권한을 부여하려면 AWSLambdaRole IAM 정책을 사용
- 또는 직접 사용자 정의 정책을 만들어
lambda:InvokeFunction권한을 허용
- 또는 직접 사용자 정의 정책을 만들어
CREATE EXTERNAL FUNCTION명령어에서도 이 IAM Role을 지정해야 함- 동일한 리전 내 다른 계정의 Lambda 함수를 IAM Role Chaning을 통해 호출하는 것도 가능
- Redshift는 Lambda와 JSON 형식으로 통신
Redshift 연합 쿼리
- 데이터베이스, 데이터 웨어하우스, 데이터 레이크 전반에 걸쳐 쿼리 및 분석 수행
- Redshift를 Amazon RDS 또는 Aurora(PostgreSQL/MySQL)과 연결
- RDS의 실시간 데이터를 Redshift 쿼리 내에 직접 포함할 수 있음
- ETL 파이프라인 구축이 불필요
- 원격 데이터베이스로 연산을 오프로드하여 데이터 이동을 최소화
- Redshift 클러스터와 RDS/Aurora 간의 연결을 설정해야 함
- 두 리소스를 동일한 VPC 서브넷에 두거나, VPC 피어링을 사용할 수 있음
- 자격 증명은 AWS Secrets Manager에 저장해야 함
- 해당 Secrets를 Redshift 클러스터의 IAM Role에 포함시켜야 함
CREATE EXTERNAL SCHEMA명령을 사용하여 연결- 이 방식을 통해 S3/Redshift Spectrum에도 연결 가능
SVV_EXTERNAL_SCHEMAS뷰에는 사용 가능한 외부 스키마 목록이 포함되어 있음- 외부 데이터 소스에 대한 읽기 전용 접근만 가능
- 외부 데이터베이스에서 비용 발생
- Redshift에서 RDS/Aurora를 쿼리할 수는 있지만, RDS/Aurora에서 Redshift를 쿼리할 수는 없음
Redshift 시스템 테이블 및 뷰
- Redshift의 작동 상태에 대한 정보를 포함
- 시스템 테이블/뷰의 종류
- SYS 뷰 : 쿼리 및 워크로드 사용을 모니터링
- STV 테이블 : 현재 시스템 데이터의 스냅샷을 담은 임시 데이터를 포함
- SVV 뷰 : STV 테이블을 참조하는 DB 객체 메타데이터를 포함
- STL 뷰 : 디스크에 영구적으로 기록된 로그로부터 생성됨
- SVCS 뷰 : 메인 클러스터 및 동시성 확장 클러스터의 쿼리 세부 정보를 포함
- SVL 뷰 : 메인 클러스터의 쿼리 세부 정보를 포함
- 많은 시스템 모니터링 뷰 및 테이블은 프로비저닝된 클러스터 전용이며, 서버리스에는 적용되지 않음
Redshift Data API
- Redshift 클러스터에 대해 SQL 문을 실행하기 위한 보안 HTTP 엔드포인트 제공
- 프로비저닝 또는 서버리스 지원
- 단일 쿼리 또는 배치 쿼리 지원
- 비동기 방식으로 동작
- 연결을 직접 관리할 필요 없음
- 드라이브가 필요하지 않음
- 비밀번호는 API를 통해 전송되지 않음
- AWS Secrets Manager 또는 임시 자격 증명 사용
- AWS SDK를 통해 호출 가능
- C++, Go, Java, JavaScript, .NET, Node.js, PHP, Python, Ruby 지원
- AWS CloudTrail이 API 호출 내역을 캡처함
Redshift Data API 기타 사용 사례
- 애플리케이션 통합
- REST 엔드포인트로 활용 가능
- 다양한 AWS 서비스와 통합 가능
- ETL 오케스트레이션
- AWS Step Functions와 연동하여 서버리스 데이터 처리 워크플로우 구축 가능
- 이벤트 기반 ETL 수행 가능
- SageMaker 노트북에서 접근 가능
- ETL 오케스트레이션
- Amazon EventBridge와 함께 사용 가능
- 애플리케이션 → Lambda로 데이터 스트리밍 가능
- 이 때 WithEvent 파라미터를 true로 설정해야 함
- Data API 작업을 예약하여 주기적으로 실행 가능
- 애플리케이션 → Lambda로 데이터 스트리밍 가능
Redshift Data API 세부 사항
- 최대 한도
- 쿼리 실행 시간 : 24시간
- 활성 쿼리 수 : 500개
- 쿼리 결과 크기 : 100MB
- 결과 보존 시간 : 24시간
- 쿼리 문 크기 : 100KB
- 쿼리 패킷당 데이터 크기 : 64KB
- 클라이언트 토큰 보존 시간 : 8시간
- 초당 트랜잭션 제한 : ExecuteStatement 기준 30TPS
- 지원되는 API 호출
- ExecuteStatement, BatchExecuteStatement
- DescribeStatement, DescribeTable
- GetStatementResult, CancelStatement
- 사용자는 동일한 IAM Role 또는 동등한 권한을 가져야 해당 쿼리 문에 대해 작업 가능
- 클러스터는 반드시 VPC 내에 있어야 함
'CERTIFICATES > AWS DEA-C01' 카테고리의 다른 글
| Container (0) | 2025.10.14 |
|---|---|
| Compute (0) | 2025.10.14 |
| Migration and Transfer (0) | 2025.10.14 |
| Storage (0) | 2025.09.30 |
| Data Engineering Fundamentals (1) | 2025.09.28 |